
冯若航
2023-05-10
AI大模型与向量数据库
新 AI 应用在过去一年中出现了指数爆炸的增长态势,而这些应用面临的一个共同挑战是如何大规模地存储与查询以向量表示的 AI Embedding。本文聚焦被 AI 炒火了的向量数据库,介绍了AI嵌入与向量存储检索的基本原理,并用一个具体的知识库检索案例来串联介绍向量数据库插件 PGVECTOR 的功能、性能、获取与应用。
AI是怎么工作的
GPT 展现出来了强大的智能水平,它的成功有很多因素,但在工程上关键的一步是:神经网络与大语言模型将一个语言问题转化为数学问题,并使用工程手段高效解决了这个数学问题。
对于AI来说,各种各样的知识与概念在内部都使用数学向量来存储表示输入输出。将词汇/文本/语句/段落/图片/音频各种对象转换为数学向量的这个过程被叫做嵌入(Embedding)。
例如 OpenAI 就使用 1536 维的浮点数向量空间。当你问 ChatGPT 一个问题时,输入的文本首先被编码转换成为一个数学向量,才能作为神经网络的输入。而神经网络的直接输出结果,也是一个向量,向量被重新解码为人类的自然语言或其他形式,再呈现到人类眼前。
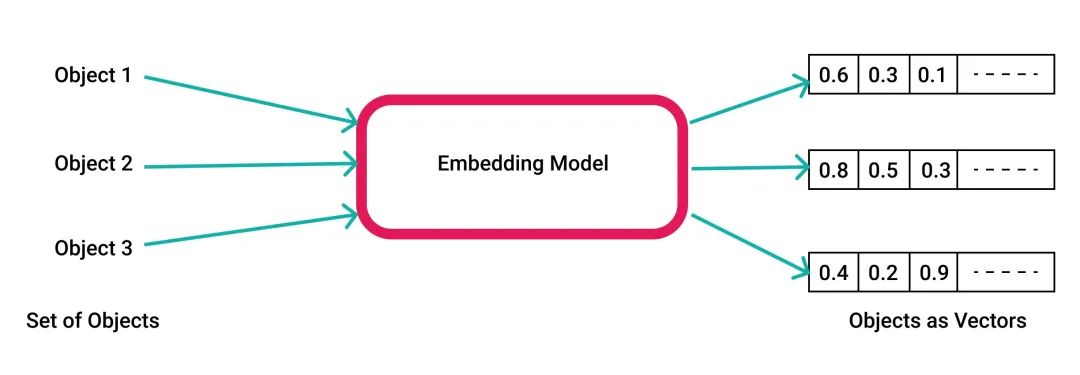
人工智能大模型的“思考过程”,在数学上就是一系列向量与矩阵之间的加乘正逆运算。这种向量对于人类来说过于抽象,无法理解。但这种形式很适合使用 GPU/FPGA/ASIC 这样的专用硬件来高效实现 —— AI 有了一个硅基的仿生大脑,带有更多的神经元,更快的处理速度,以及更强大的学习算法,惊人的智能水平,高速自我复制与永生的能力。
语言大模型解决的是 编码 - 运算 - 输出 的问题,但是只有计算是不够的,还有一个重要的部分是记忆。大模型本身可以视作人类公开数据集的一个压缩存储,这些知识通过训练被编码到了模型中,内化到了模型的权重参数里。而精确性的,长期性的,过程性的,大容量的外部记忆存储,就需要用到向量数据库了。
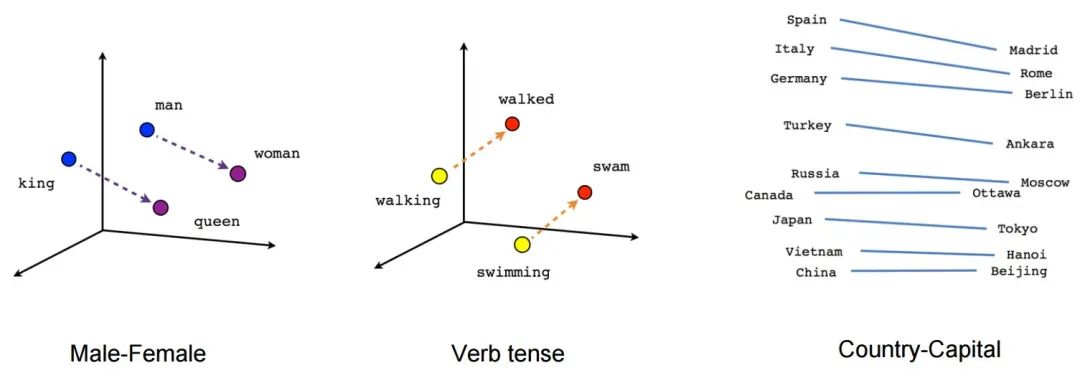
所有的概念都可以用向量来表示,而向量空间有一些很好的数学性质,比如可以计算两个向量的“距离”。这意味着任意两个抽象概念之间的“相关性”,都可以用对应编码向量的距离来衡量。
这个看上去简单的功能却有着非常强大的效果,例如最经典的应用场景就是搜索。比如,您可以预处理你的知识库,将每个文档都是用模型转换成抽象向量存储在向量数据库中,当你想要检索时,只需要将您的问题也用模型编码成为一个一次性的查询向量,并在数据库中找到与此查询向量“**距离最近“**的文档作为回答返回给用户即可。
通过这种方式,一个模糊而困难的自然语言处理问题,转换成为了一个简单清晰的数学问题。而向量数据库,就可以用来高效地解决这个数学问题。
向量数据库能干什么?
数据库有事务处理(OLTP)与数据分析(OLAP)两大核心场景,向量数据库自然也不例外。典型的事务处理场景包括:知识库,问答,推荐系统,人脸识别,图片搜索,等等等等。知识问答:给出一个自然语言描述的问题,返回与这些输入最为接近的结果;以图搜图:给定一张图片,找出与这张图片在逻辑上最接近的其他相关图片。
这些功能说到底都是一个共同的数学问题:**向量最近邻检索(KNN):**给定一个向量,找到距离此向量最近的其他向量。
典型的分析场景是聚类:将一系列向量按照距离亲疏远近分门别类,找出内在的关联结构,并对比急簇之间的差异。
PG向量插件 PGVECTOR
市面上有许多向量数据库产品,商业的有 Pinecone,Zilliz,开源的有 Milvus,Qdrant 等,基于已有流行数据库以插件形式提供的则有 pgvector 与 Redis Stack。
在所有现有向量数据库中,pgvector 是一个独特的存在 —— 它选择了在现有的世界上最强大的开源关系型数据库 PostgreSQL 上以插件的形式添砖加瓦,而不是另起炉灶做成另一个专用的“数据库” [1]。pgvector 有着优雅简单易用的接口,不俗的性能表现,更是继承了PG生态的超能力集合。
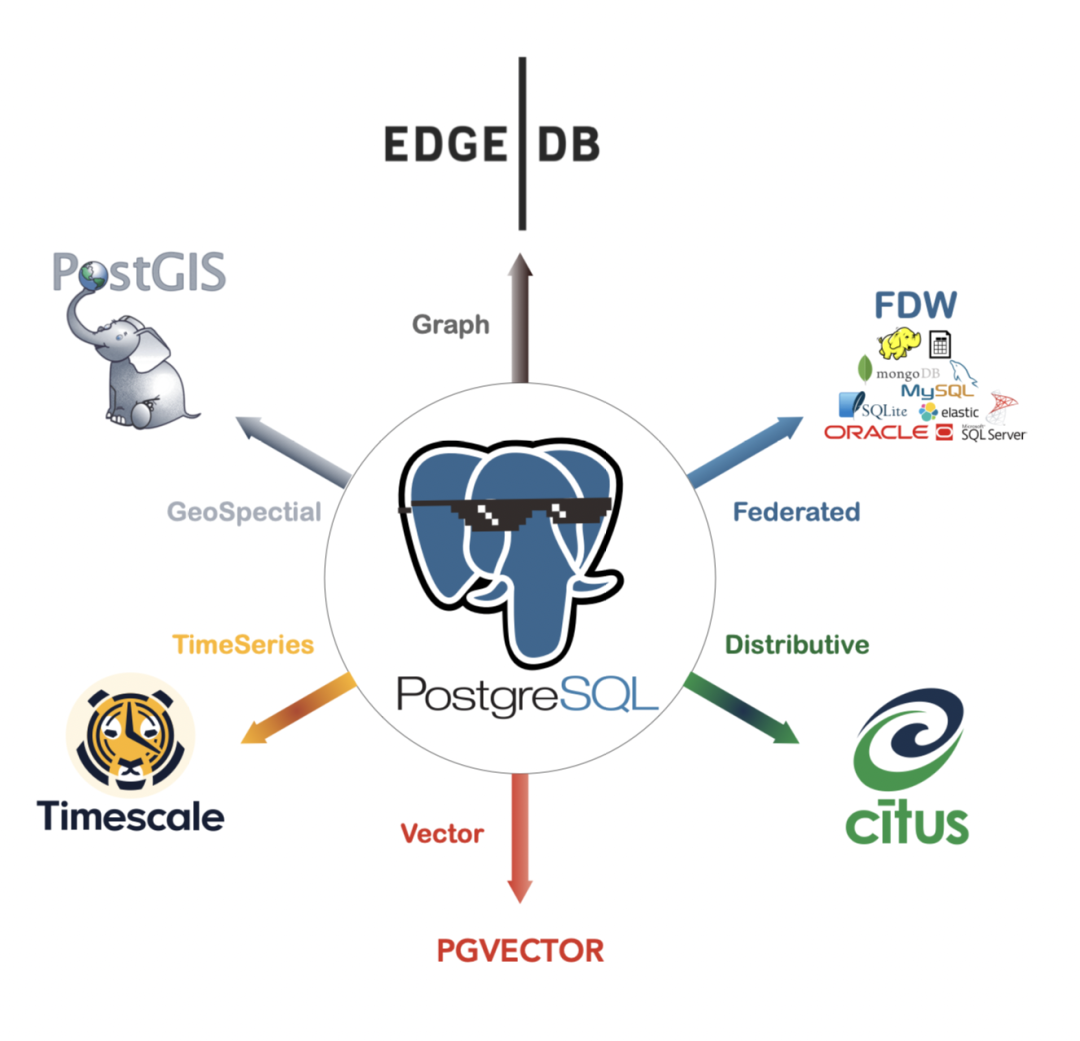
一个合格的向量数据库,首先得是一个合格的数据库,而从零开始做到这一点并不容易。比起使用一种全新的独立数据库品类,为现有数据库加装向量搜索的能力显然是一个更为务实,简单,经济的选择。
PGVECTOR 知识检索案例
下面我们通过一个具体的例子演示 PGVECTOR 这样的向量数据库是如何工作的。
模型
OpenAI 提供了将自然语言文本转换为数学向量的 API :例如 text-embedding-ada-002 ,便可以将最长2048~8192个字符的句子/文档转换为一个 1536 维的向量。但是这里我们选择使用 HuggingFace 上的 shibing624/text2vec-base-chinese 模型替代 OpenAI 的 API 完成文本到向量的转换。
这个模型针对中文语句进行了优化,尽管没有 OpenAI 模型有那样深入的语义理解能力,但它是开箱即用的,使用 pip install torch text2vec 即可完成安装,而且可以在本地CPU上运行,完全开源免费。您可以随时换用其他模型:基本用法是类似的。
from text2vec import SentenceModel
# 自动下载并加载模型
model = SentenceModel('shibing624/text2vec-base-chinese')
sentence = '这里是你想编码的文本输入'
vec = model.encode(sentence)
使用以上代码片段即可将任意长度在512内的中文语句编码为 768 维的向量。拆分后只需要调用模型的编码(encode)方法,即可将文本转换为数学向量。对于很长的大文档,您需要合理地将文档与知识库拆分成一系列长度得当的段落。
存储
编码后的结果,在 PostgreSQL 中使用形如 ARRAY[1.1,2.2,...] 这样的浮点数组形式表示。这里我们跳过数据清洗灌入的琐碎细节,总之在一番操作后有了一张语料数据表 sentences,一个 txt 字段来存储原始文本表示,并使用一个额外的 vec 字段存储文本编码后的 768 维向量。
CREATE EXTENSION vector;
CREATE TABLE sentences(id BIGINT PRIMARY KEY, -- 标识 txt TEXT NOT NULL, -- 文本 vec VECTOR(768) NOT NULL -- 向量);
这张表和普通的数据库表并没有任何区别,你可以用一模一样的增删改查语句。特殊的地方在于 pgvector 扩展提供了一种新的数据类型 VECTOR ,以及相应的几种距离函数、运算符与对应的索引类型,允许您高效地完成向量最近邻搜索。
查询
这里我们只需要用一个简易的 Python 小脚本,就可以制作一个全文模糊检索的命令行小工具:
# !/usr/bin/env python3
from text2vec import SentenceModel
from psycopg2 import connect
model = SentenceModel('shibing624/text2vec-base-chinese')
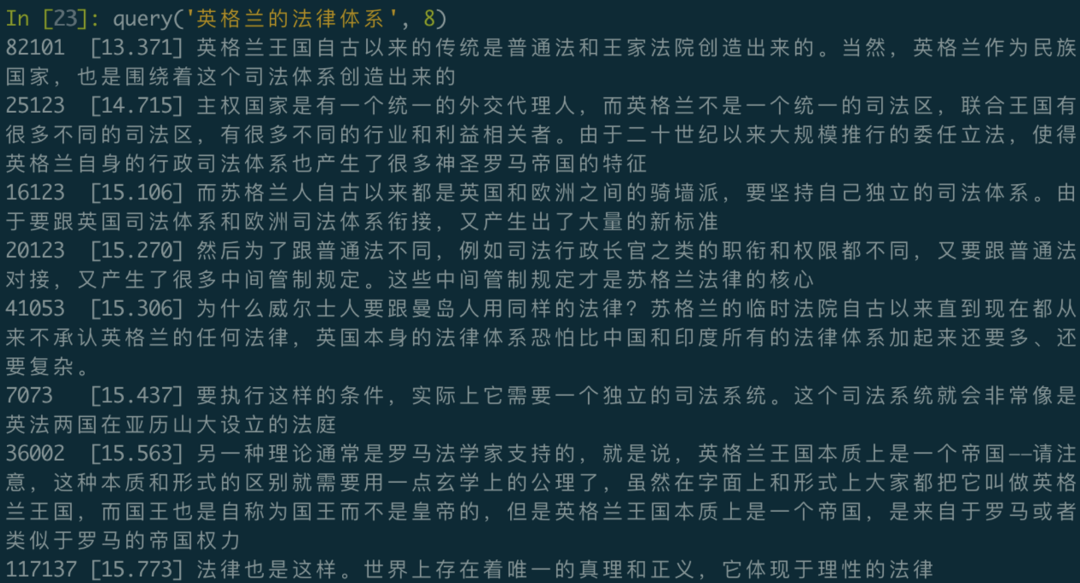
def query(question, limit=64):
vec = model.encode(question) # 生成一个一次性的编码向量,默认查找最接近的64条记录
item = 'ARRAY[' + ','.join([str(f) for f in vec.tolist()]) + ']::VECTOR(768)'
cursor = connect('postgres:///').cursor()
cursor.execute("""SELECT id, txt, vec <-> %s AS d FROM sentences ORDER BY 3 LIMIT %s;""" % (item, limit))
for id, txt, distance in cursor.fetchall():
print("%-6d [%.3f]\t%s" % (id, distance, txt))
PGVECTOR 的性能
当功能、正确性、安全性满足需求后,用户的目光就会转向性能。PGVECTOR 有着不错的性能表现,尽管比起专用的高性能向量计算Library来说有些差距,但性能对于生产环境中使用已经是绰绰有余了。
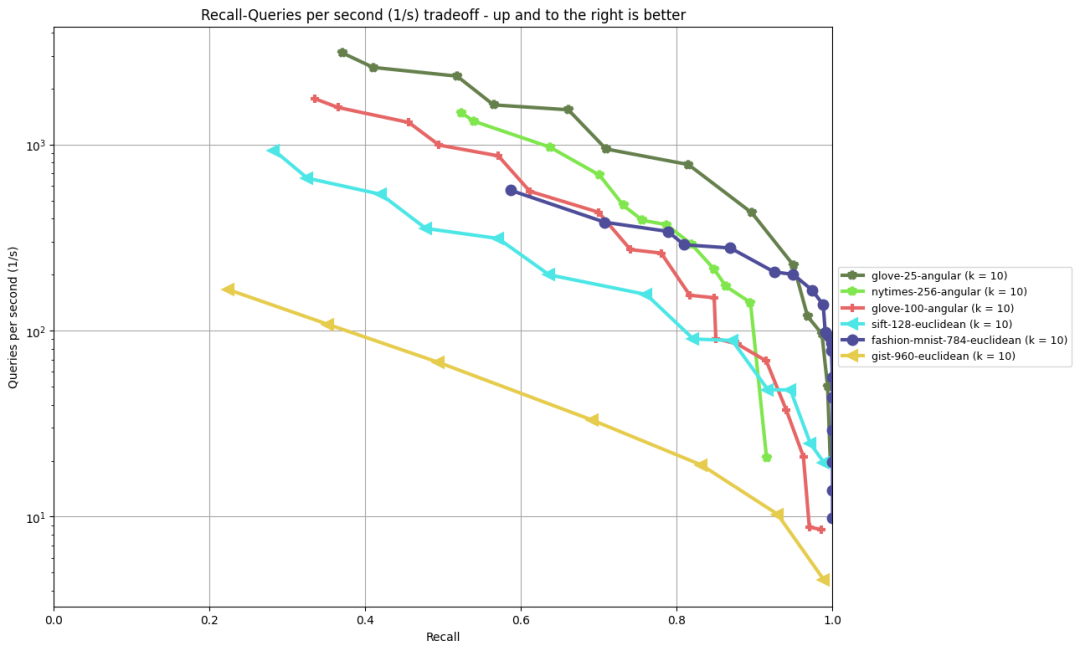
对于向量数据库来说,最近邻查询的延迟是一个重要的性能指标,ANN-Benchmark 则是一个相对权威的最近邻性能评测基准[2]。pgvector 的索引算法是 ivfflat ,在几个常见的基准测试中表现如下图所示:
为了对 pgvector 的性能表现在直觉上有一个把握,在 M1 Max 芯片 Macbook 下单核运行一些简单的测试:从1百万条随机 1536 维向量(正好是 OpenAI 的输出向量维度)中找出余弦距离最近的TOP 1 ~ 50 条向量,每次耗时大约 8ms 。从 1 亿条随机 128 维向量 (SIFT图像数据集的维度)中找出 L2 欧几里得距离 TOP 1 向量耗时 5ms,TOP 100 耗时也只要 21ms 。
-- 1M 个 1536 维向量,随机取 TOP1~50,余弦距离, 单核:插入与索引耗时均为5~6分钟,大小8GB左右。随机向量最近邻 Top1 召回:8ms
DROP TABLE IF EXISTS vtest;
CREATE TABLE vtest ( id BIGINT, v VECTOR(1536) );
TRUNCATE vtest;
INSERT INTO vtest SELECT i, random_array(1536)::vector(1536) FROM generate_series(1, 1000000) AS i;
CREATE INDEX ON vtest USING ivfflat (v vector_cosine_ops) WITH(lists = 1000);
WITH probe AS (SELECT random_array(1536)::VECTOR(1536) AS v)
SELECT id FROM vtest ORDER BY v <=> (SELECT v FROM probe) limit 1;
-- 简易SIFT ,1亿个128维向量,测试L2距离,召回1个最近向量, 5 ms, 召回最近100个向量:21ms
DROP TABLE IF EXISTS vtest;
CREATE TABLE vtest( id BIGINT, v VECTOR(128) );
TRUNCATE vtest;
INSERT INTO vtest SELECT i, random_array(128)::vector(128) FROM generate_series(1, 100000000) AS i;
CREATE INDEX ON vtest USING ivfflat (v vector_l2_ops) WITH(lists = 10000);
WITH probe AS (SELECT random_array(128)::VECTOR(128) AS v)
SELECT id FROM vtest ORDER BY v <-> (SELECT v FROM probe) limit 1; -- LIMIT 100
使用真实的 SIFT 1M 数据集来测试,找出测试集中1万条向量在1百万条基础向量集中的最近邻单核总共只需18秒,单次查询的延迟在 1.8 ms ,折合单核500 QPS,可以说是相当不错了。当然对于 PostgreSQL 这样的成熟数据库来说,你总可以简单地通过加核数与拖从库来近乎无限地扩容其QPS吞吐量。
-- SIFT 1M 数据集,128维embedding,使用ivfflat索引, L2距离,10K测试向量集。
DROP TABLE IF EXISTS sift_base;
CREATE TABLE sift_base (id BIGINT PRIMARY KEY , v VECTOR(128));
DROP TABLE IF EXISTS sift_query;
CREATE TABLE sift_query (id BIGINT PRIMARY KEY , v VECTOR(128));
CREATE INDEX ON sift_base USING ivfflat (v vector_l2_ops) WITH(lists = 1000);
-- 一次性寻找 sift_query 表中 10000 条向量在 sift_base 表中的最近邻 Top1: 单进程 18553ms / 10000 Q = 1.8ms
explain analyze SELECT q.id, s.id FROM sift_query q ,LATERAL (SELECT id FROM sift_base ORDER BY v <-> q.v limit 1) AS s;
-- 单次随机查询耗时在 个位数毫秒
WITH probe AS (SELECT v AS query FROM sift_query WHERE id = (random() * 999)::BIGINT LIMIT 1)
SELECT id FROM sift_base ORDER BY v <-> (SELECT query FROM probe) LIMIT 1;
如何获取 PGVECTOR?
最后,我们来聊一聊,如何快速获取一个可用的 PGVECTOR ?
在以前,PGVECTOR 需要自行下载编译安装,所以我提了一个 Issue 把它加入到 PostgreSQL 全球开发组的官方仓库中[5]。你只需要正常使用 PGDG 源即可直接 yum install pgvector_15 完成安装。在安装了 pgvector 的数据库实例中使用 CREATE EXTENSION vector 即可启用此扩展。
CREATE EXTENSION vector;
CREATE TABLE items (vec vector(2));
INSERT INTO items (vec) VALUES ('[1,1]'), ('[-2,-2]'), ('[-3,4]');
SELECT *, vec <=> '[0,1]' AS d FROM items ORDER BY 2 LIMIT 3;
更简单的选择是本地优先的开源 RDS PostgreSQL 替代 —— Pigsty ,在三月底发布的v2.0.2 中, pgvector 已经默认启用,开箱即用。您可以在一台全新虚拟机上一键完成安装,自带时序地理空间向量插件,监控备份高可用齐全。分文不收,立等可取。

Supabase,Neon 也提供了带有 pgvector 插件的付费托管 PostgreSQL 服务,AWS RDS for PostgreSQL 也已经在五月初刚刚支持了此扩展 。提供托管服务的完整供应商列表可以参考 pgvector 的 Github Issue [6]。
参考
[2] ANN性能评测基准
[4] 文本与代码嵌入
[5] Add official RPM package and inclusion in PGDG YUM repository