
在线幻灯片:人人都能用上的 PostgreSQL 扩展
第一部分:引言#
0. 人人都能用上的扩展#
大家好,这次演讲的题目是「人人都能用上的扩展」。
它讨论的是 PostgreSQL 扩展的交付,以及一个共享的交付层,如何同时让用户、扩展作者、厂商和 PostgreSQL 内核开发者受益。
1. 我是谁#
我是冯若航,Pigsty 的作者和维护者。Pigsty 是一个开源 PostgreSQL 发行版。
我也是 pgext.cloud 的建设者。pgext.cloud 是一个面向 PostgreSQL 扩展的开源交付层。
过去两年里,我一直在为数百个扩展做编目、构建、打包和测试,覆盖不同 PostgreSQL 版本和 Linux 平台。所以这次分享不是理论推演,而是一份一线报告。

2. 可扩展性很重要#
可扩展性很重要。两年前,我写过一篇文章,说 PostgreSQL 正在吞噬数据库世界。
当时的论点很简单:PostgreSQL 的成功源自可扩展性。它允许生态快速前进,而不必把每一个新想法都塞进内核。这是 PostgreSQL 的超能力。但它也带来了一个很现实的问题。
如果 PostgreSQL 是通过扩展来成长的,那么扩展交付本身就成了系统的一部分。
只有可扩展性还不够。一个扩展只有在能被发现、能被安装、能被信任时,才真正有意义。
这就是我开始收集和打包扩展的原因。

3. 两年之后#
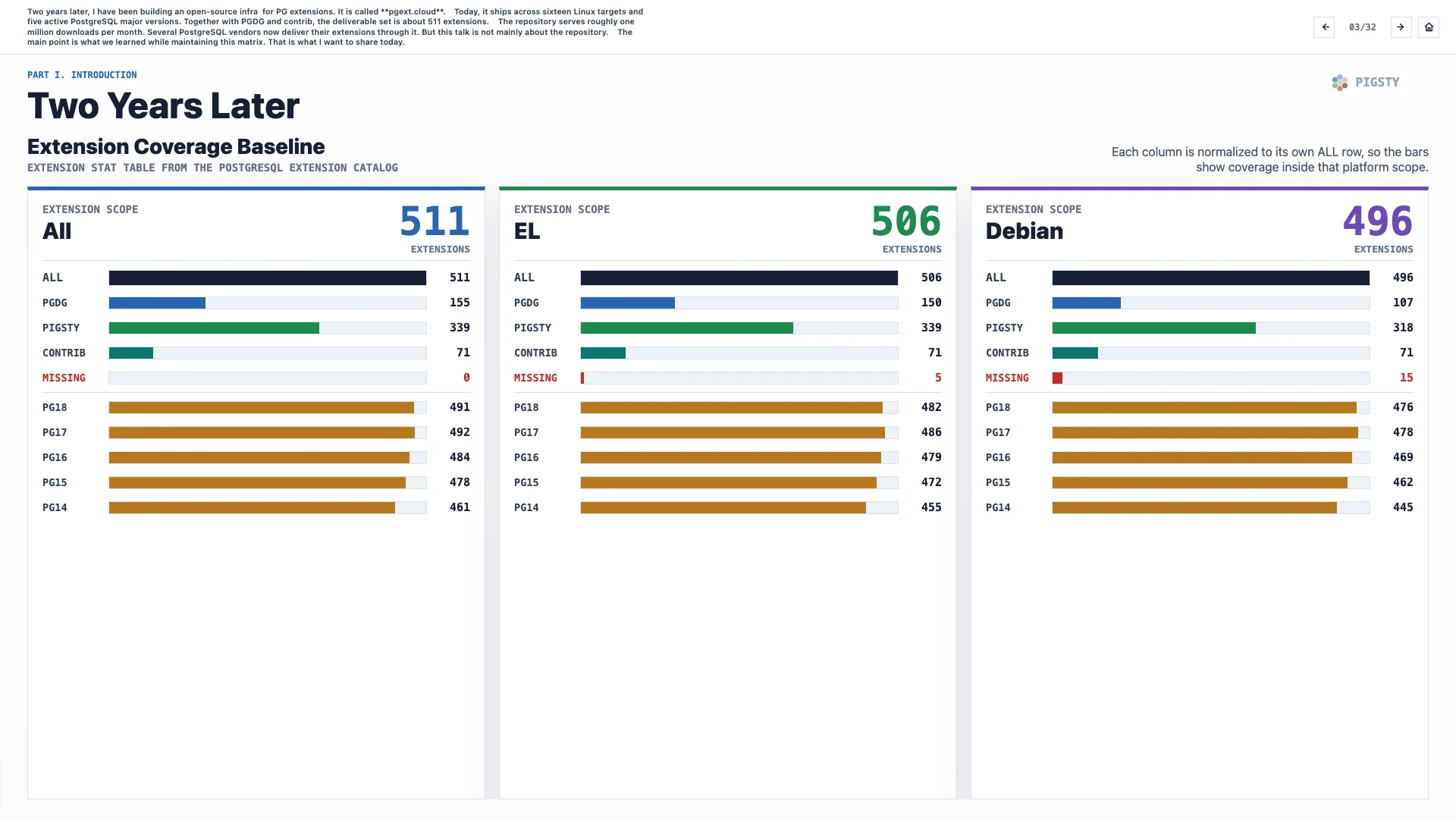
两年之后,我已经搭建了一套面向 PG 扩展的开源基础设施,叫 pgext.cloud。
今天,它覆盖 16 个 Linux 目标平台和 5 个活跃的 PostgreSQL 大版本。加上 PGDG 和 contrib,可交付的扩展集合大约有 511 个。
这个仓库每月提供大约一百万次下载。现在已有几家 PostgreSQL 厂商通过它交付自己的扩展。但这次演讲的重点并不是这个仓库本身。
真正重要的是,我们在维护这张矩阵时学到了什么。这才是我今天想分享的内容。
4. 谁会受益?#
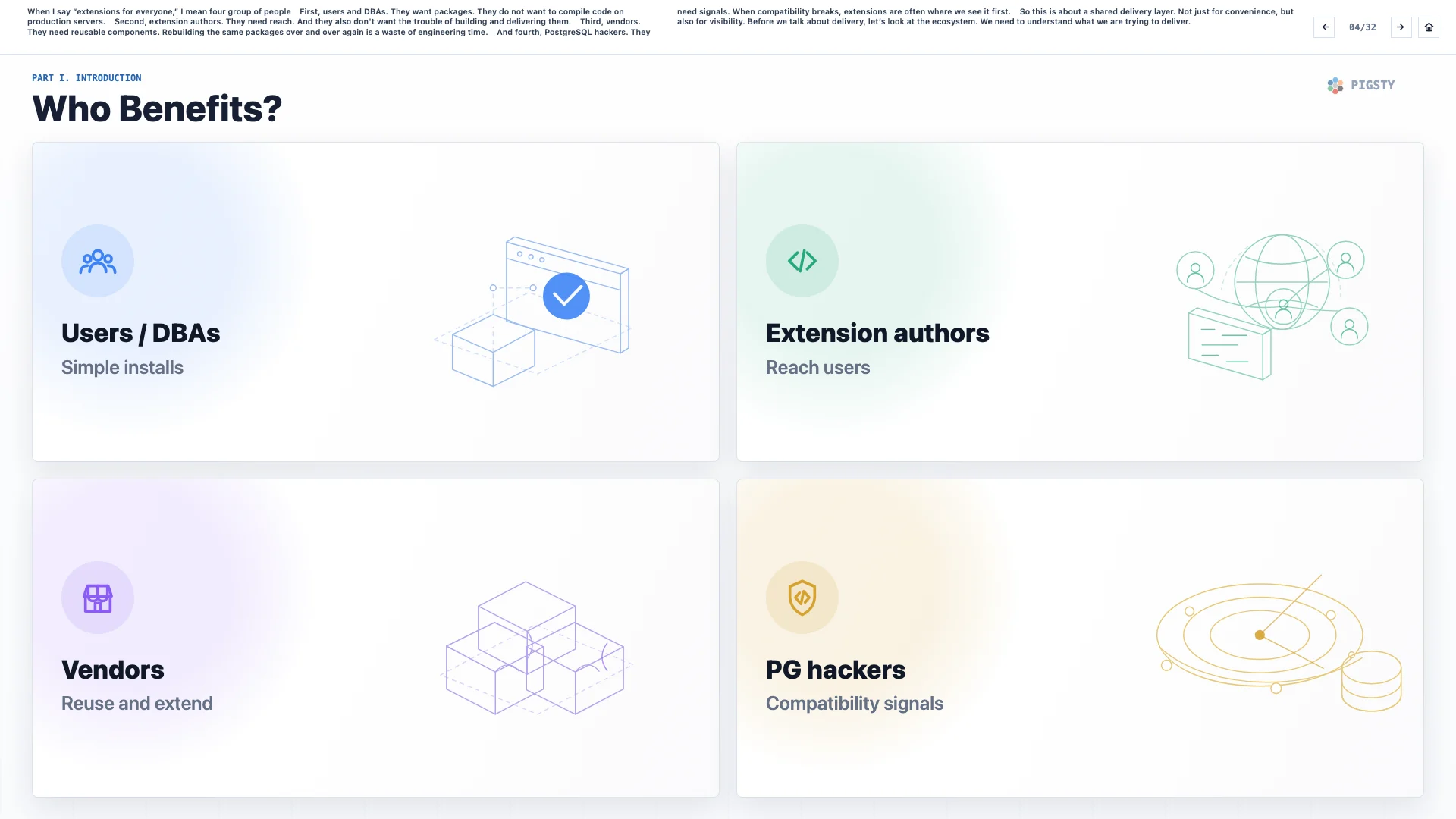
我说「人人都能用上的扩展」时,指的是四类人。
第一类是用户和 DBA。他们想要的是包,而不是在生产服务器上编译代码。
第二类是扩展作者。他们需要触达用户,也不想被构建和交付这些琐事拖住。
第三类是厂商。他们需要可复用的组件。反复重建同一批包,是对工程时间的浪费。
第四类是 PostgreSQL 内核开发者。他们需要信号。当兼容性被破坏时,扩展往往是最早暴露问题的地方。
所以这件事本质上是一个共享交付层。它不只是为了方便,也提供了可见性。在谈交付之前,我们先看一下生态本身。我们需要先理解,我们到底要交付什么。
第二部分:生态全景#
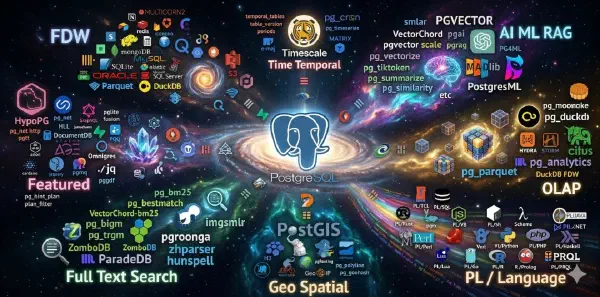
5. 星系#
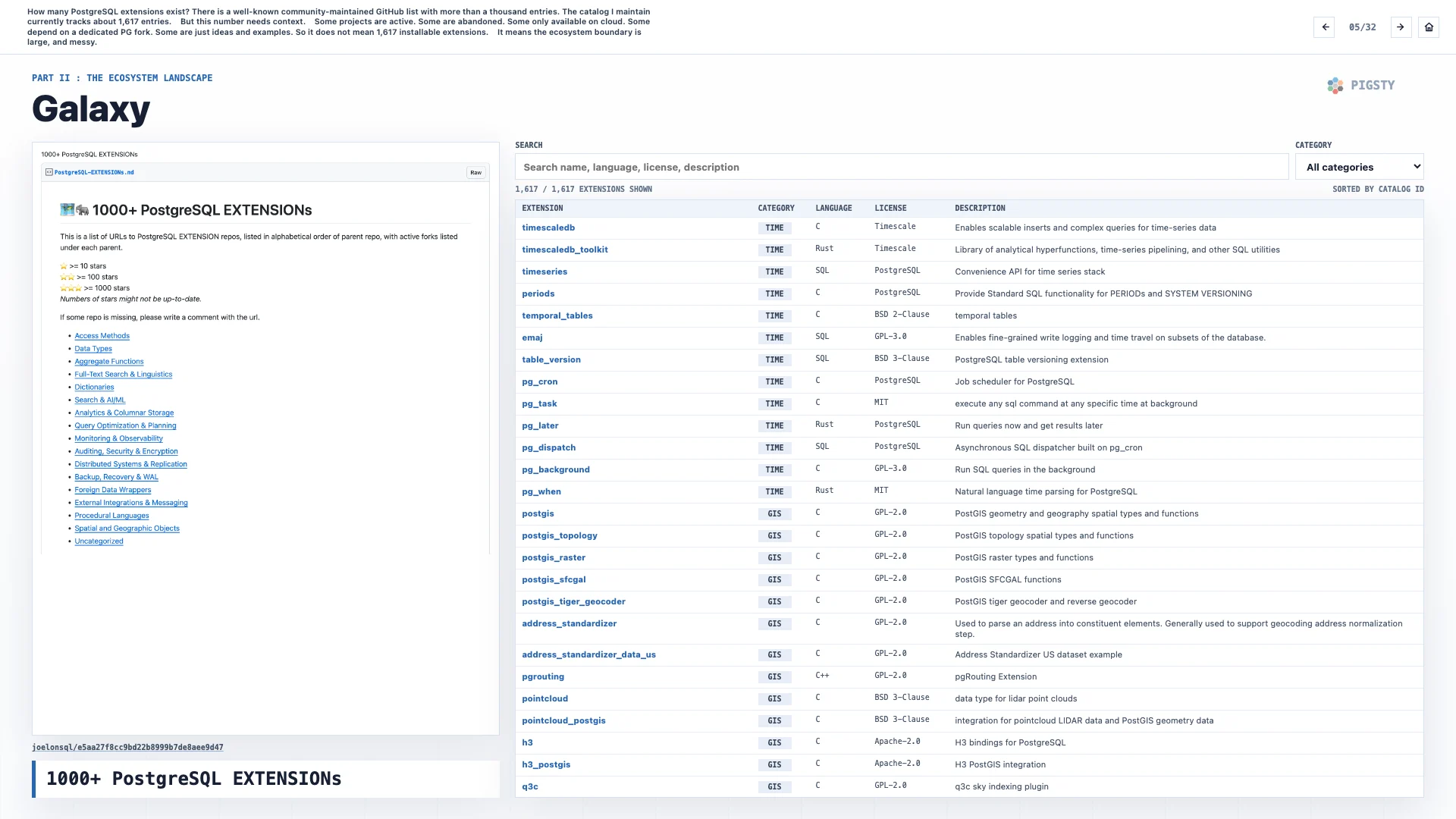
PostgreSQL 到底有多少扩展?社区里有一个很有名的、由大家共同维护的 GitHub 列表,里面有一千多个条目。我维护的目录目前跟踪了大约 1,617 个条目。
但这个数字需要放在上下文里看。
有些项目仍然活跃,有些已经废弃;有些只能在云上使用;有些依赖专门的 PostgreSQL 分叉;还有一些只是想法和示例。所以,1,617 并不意味着有 1,617 个可以直接安装的扩展。
它意味着生态的边界很大,而且很乱。
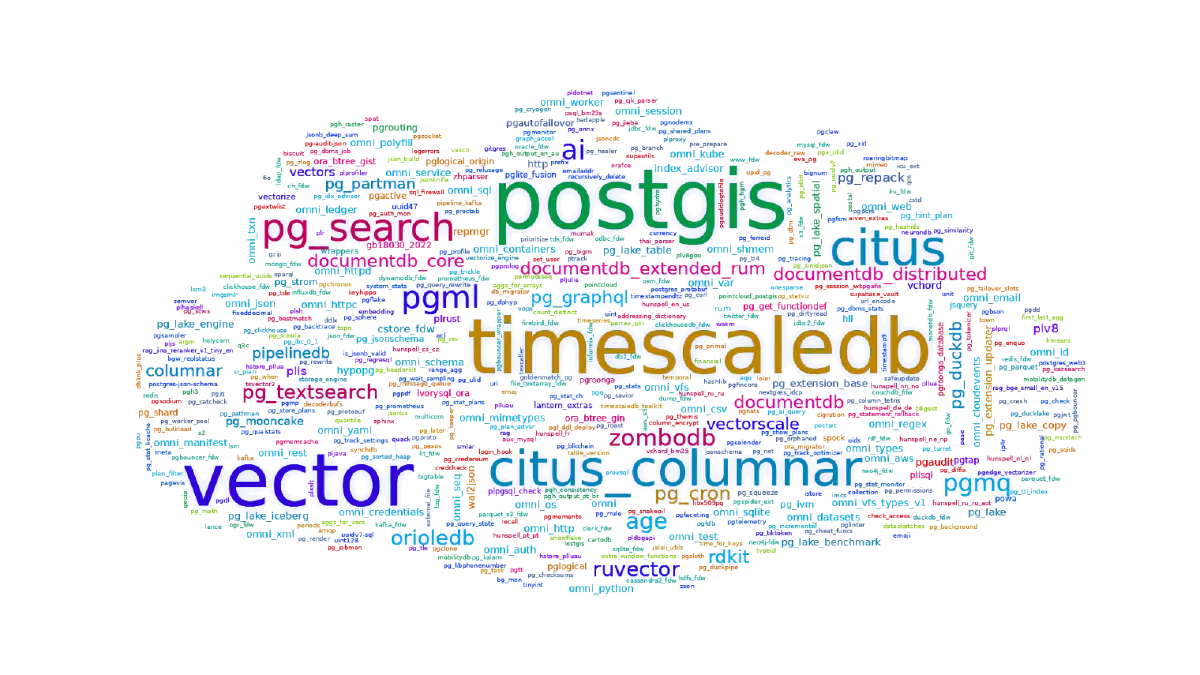
6. GitHub 星标#
第一个公开信号是 GitHub 星标。星标不能衡量质量,也不能衡量生产使用情况,而且会漏掉那些根本不托管在 GitHub 上的项目,比如 postgres 和 postgis。
但星标仍然有用。它反映了关注度、声誉和大致的认知度。排在前面的都是熟悉的名字:TimescaleDB、pgvector、Citus、pg_search、pgml、pgai、pgmq,还有很多其他项目。
如果观察分布,会发现它极度倾斜。少数扩展拿走了大部分关注度,后面是一条长尾。这是一个对数分布。
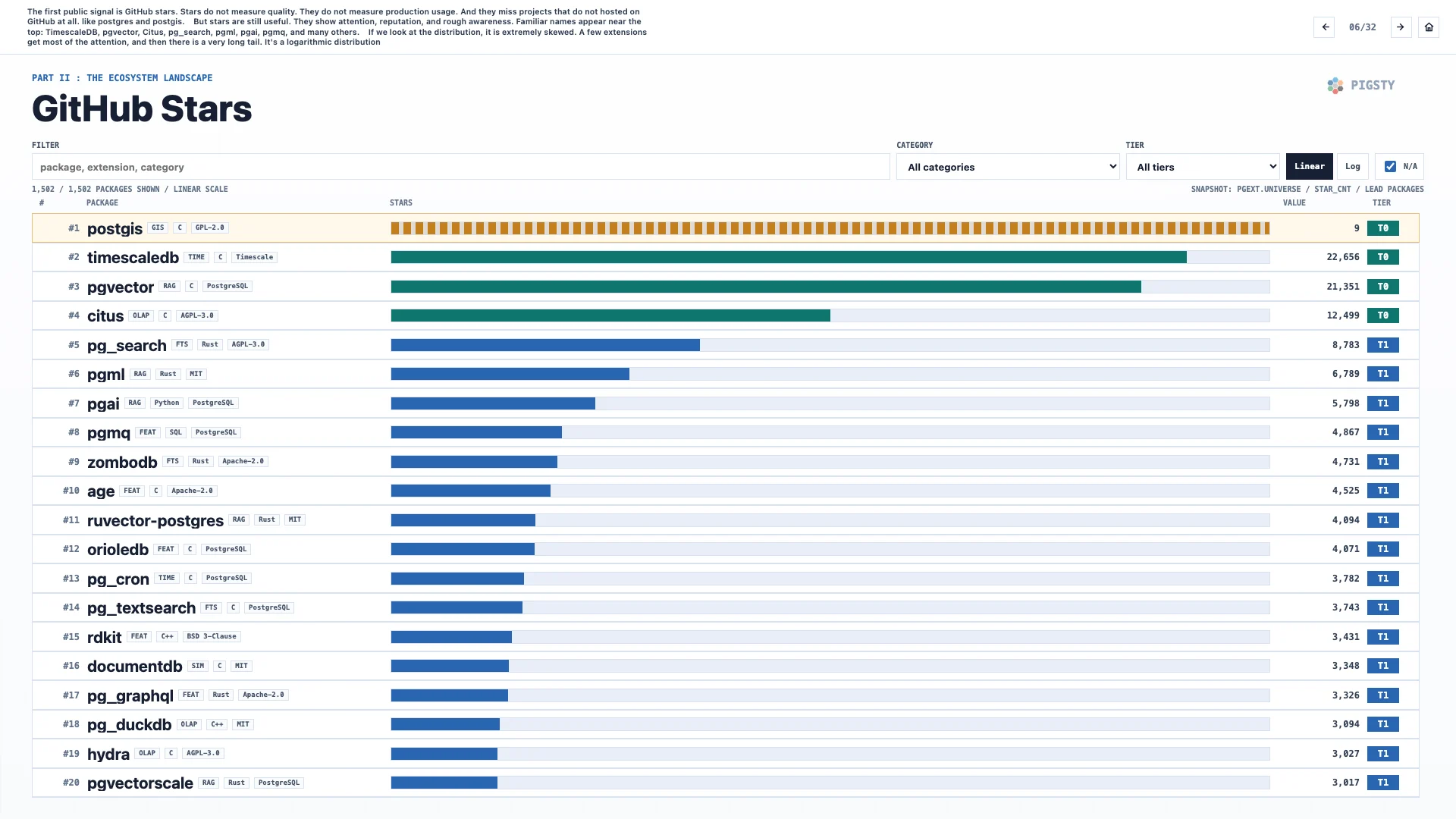
7. 星标分层#
按数量级给扩展分组,就会得到一个简单的分层模型。
第零层:四大天王。PostGIS、TimescaleDB、pgvector、Citus,每个都超过一万星。
第一层:44 个扩展,星标在一千到一万之间。
第二层:大约 152 个扩展,超过一百星。
第三层:大约 373 个扩展,超过十星。
然后是约 748 个低于十星的长尾扩展。
这不是质量排名。有些热门项目已经不再活跃,比如 pgml 或 zombodb。有些低星扩展反而非常有用。
但这些层级说明了一件事:可见的生态要比被发现的生态小得多。把第零层到第三层加起来,大约是 570 个超过十星的扩展,和实际可交付的规模很接近。
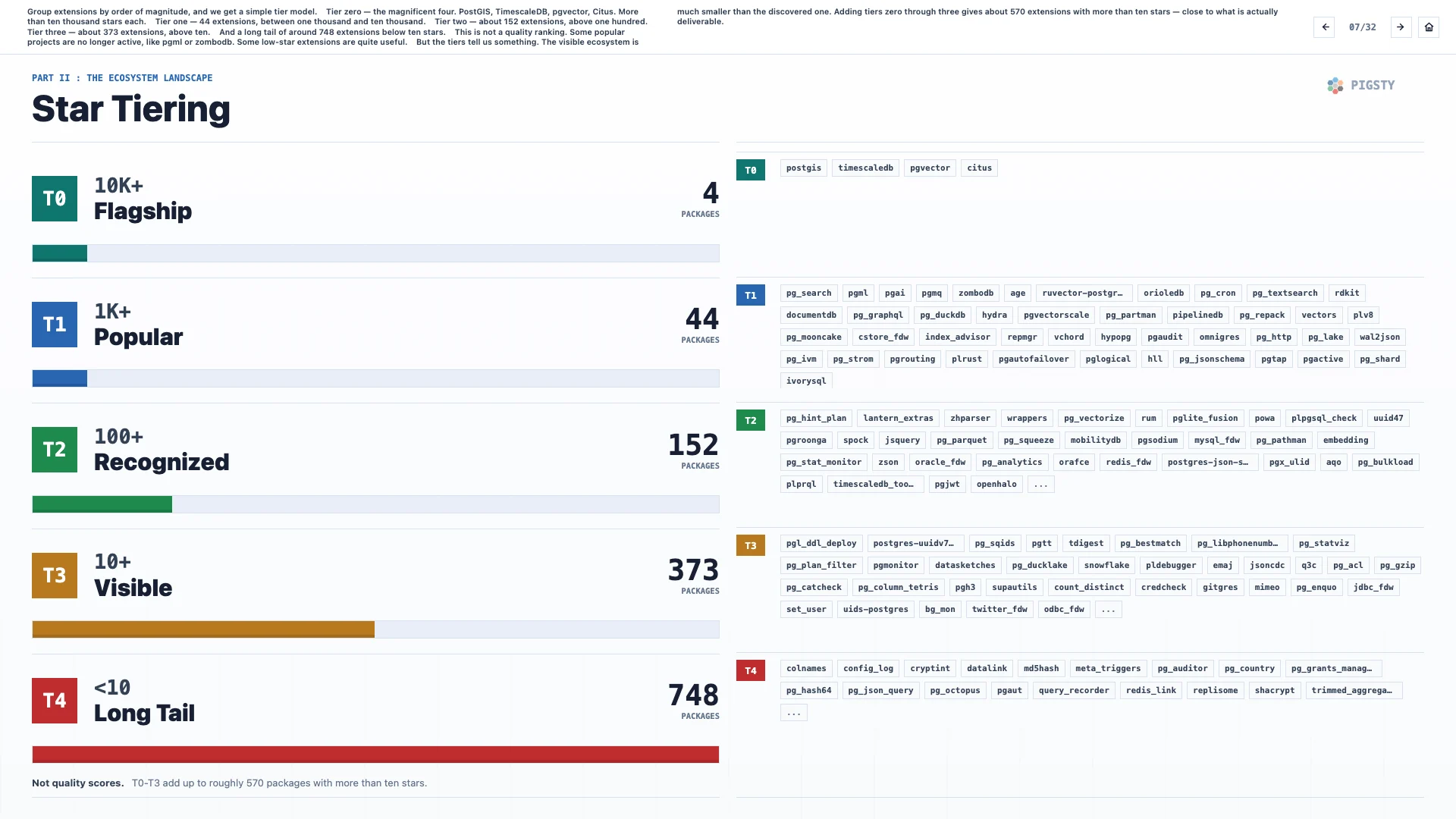
8. 扩展漏斗#
于是我们得到了一个漏斗。顶部有 1,600 个候选项。如果砍掉长尾,数量会迅速下降。
中间大约有 500 个已经被编目、打包和交付。
按来源拆开看,大约 330 个来自 Pigsty 仓库,160 个来自 PGDG,两边还有一些重叠。最底部,是 PostgreSQL 自带的 71 个 contrib 扩展。
关键在于这个形状。发现面很宽,交付范围窄一些,实际使用又更窄。
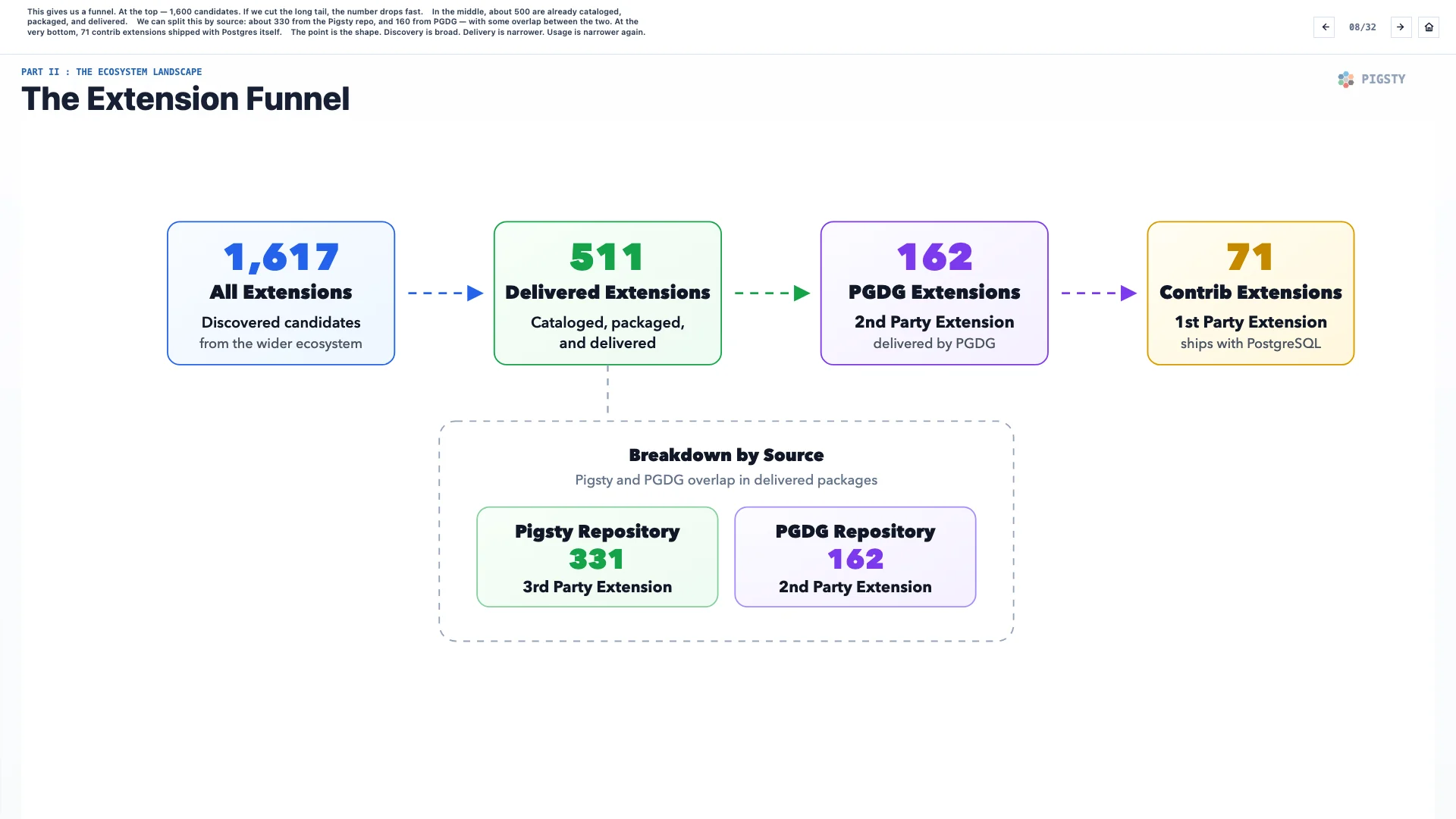
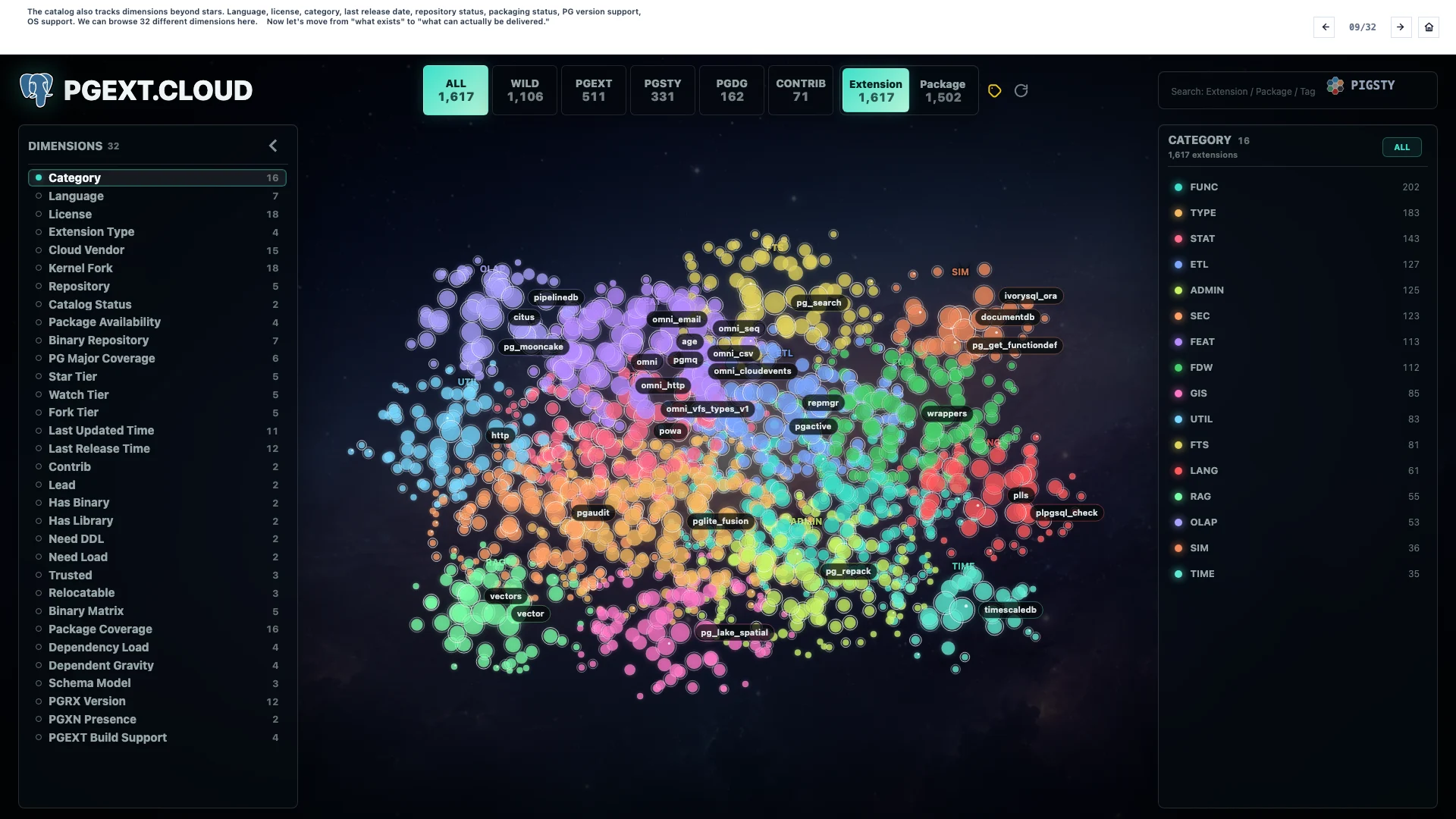
9. 维度分析#
这个目录还跟踪星标之外的很多维度:语言、许可证、分类、最近发布日期、仓库状态、打包状态、PG 版本支持、操作系统支持。这里可以浏览 32 个不同维度。
现在,我们从「存在什么」转向「什么真的可以被交付」。
第三部分:交付层#
10. 现状#
打包 PostgreSQL 扩展很难。难点不是包格式有多神秘,而是矩阵太大。我们面对的是 5 个活跃 PG 大版本乘以 16 个 Linux 平台,也就是每个扩展 80 个构建槽位。真正覆盖全部槽位的扩展只有少数。
Christoph 和 Devrim 维护的 PGDG YUM 与 APT 仓库已经完成了基础工作。它们承载了许多最重要的扩展,总共大约 150 个包。但缺口仍然存在,比如 Rust 扩展,以及一些没有被覆盖的操作系统和 PG 组合。
所以这个互补仓库的目标,就是补上这些缺口。在 PGDG 覆盖不到的地方,或者构建成本太高、难以维护的地方,额外交付包。总体上大约新增 300 个扩展包。

11. 取舍#
这背后有一个真实的取舍。C 扩展构建得很快,Rust 扩展则不是。一个 Rust 扩展的构建时间,可能比所有 C 扩展加起来还长。
但用户仍然需要它们。比如自托管的 Supabase 栈大约需要十几个扩展,其中三个是 Rust 扩展。所以问题不是这件事有没有必要,而是这项工作应该放在哪里完成。
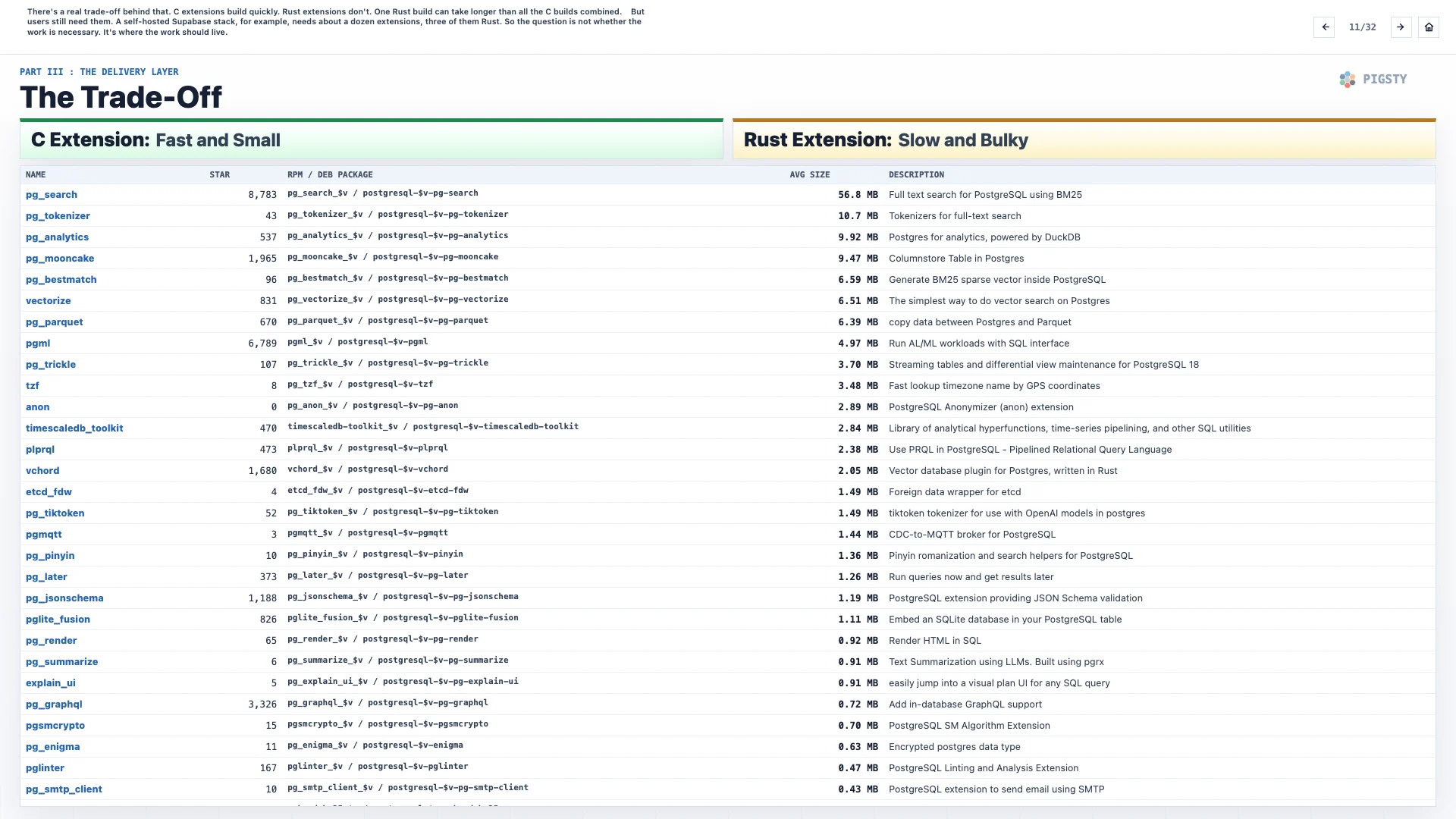
12. 为什么要做 Linux 原生包?#
容器镜像可以减少一部分矩阵。这一点我非常认可。有了容器,每个扩展只需要构建 5 个 PG 大版本乘以 2 个架构,也就是 10 个槽位,规模缩小了 8 倍。
但 Linux 原生包仍然很重要。很多用户仍然通过系统原生包管理器安装 Postgres,也就是 APT 或 YUM。而且大多数 Postgres Docker 镜像本身,也是从 PGDG APT 仓库安装 Debian 包形式的扩展。
所以,这些打包工作总要有人来做。
13. 基础设施#
为了把这些 RPM 和 DEB 扩展包交付给用户,我们围绕它搭建了一套开源基础设施。它有四个部分:用于发现的目录,用于交付的仓库,一个可选的 CLI,用来简化访问。
在它们背后,是构建矩阵。CLI 很简单,仓库很有用,但目录和构建矩阵才是大部分工程成本所在。
14. 扩展目录#
目录是事实来源。它不是一个营销页面,而是一个带结构化元数据的数据库,描述扩展的一切:维度、标签、依赖、可用性矩阵,以及如何安装、配置、构建和使用的备注。
这听起来像是枯燥的脏活。但正是这些枯燥的元数据,让系统的其他部分能够可预测地运行。有了这些数据,你甚至可以让 Codex 用一句提示词重新生成扩展星系图。
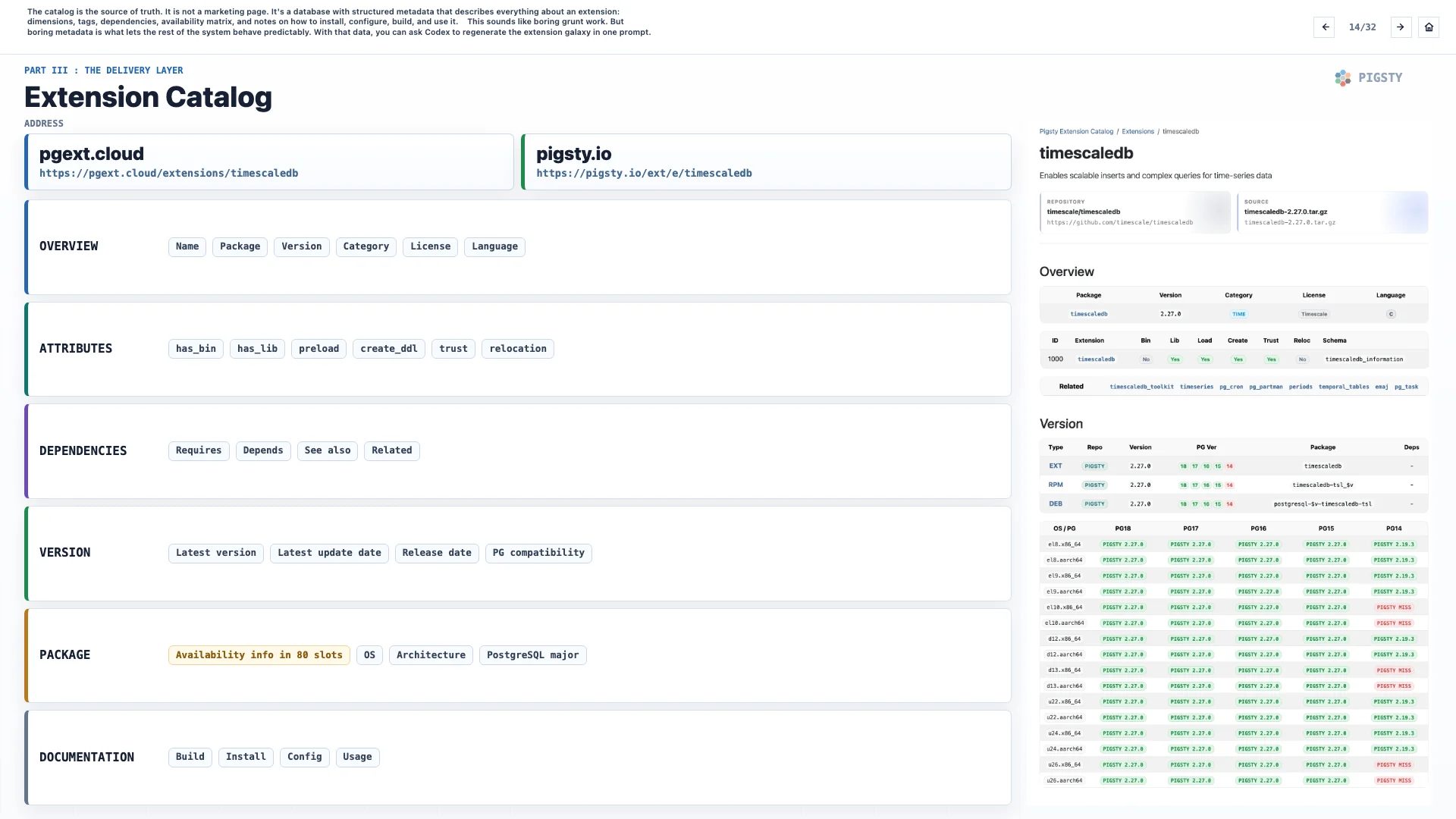
15. 目录细节#
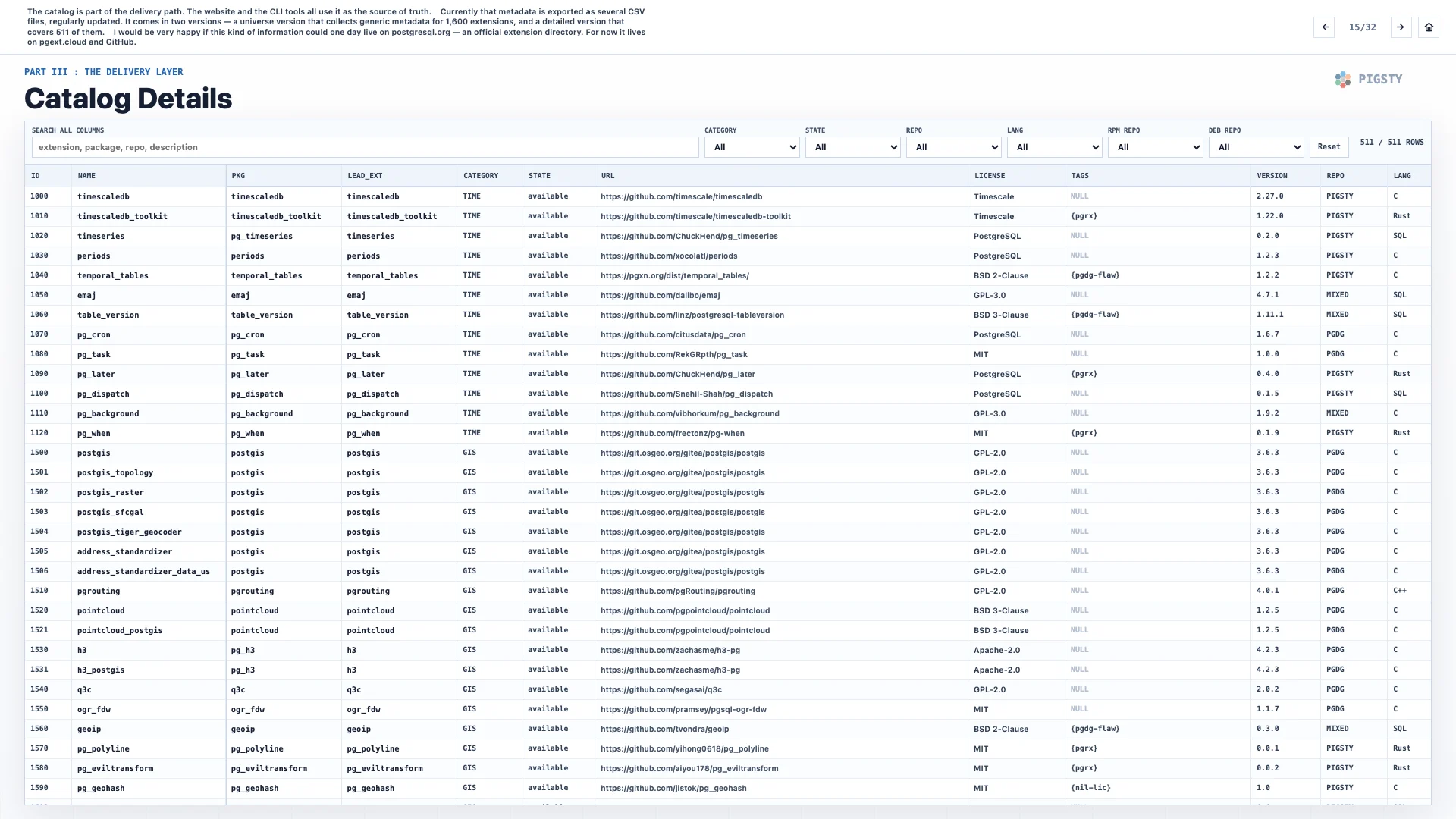
目录是交付路径的一部分。网站和 CLI 工具都把它作为事实来源。
目前这些元数据会定期导出为几个 CSV 文件。它有两个版本:一个 universe 版本,收集 1,600 个扩展的通用元数据;一个详细版本,覆盖其中 511 个扩展。
如果有一天,这类信息能放到 postgresql.org 上,成为官方扩展目录,我会非常高兴。现在它暂时放在 pgext.cloud 和 GitHub 上。
16. 目录页访问量#
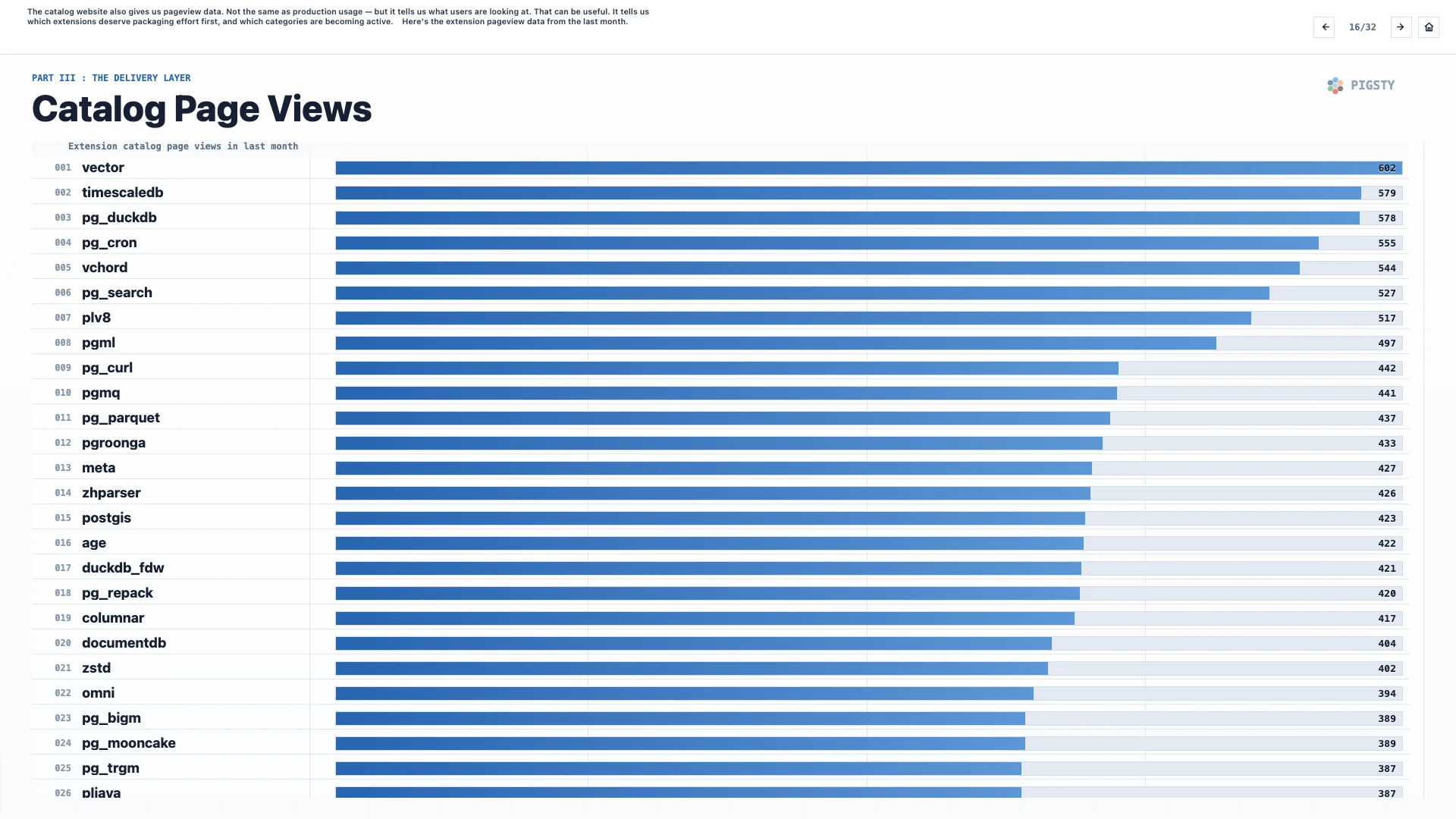
目录网站也会给出页面访问量数据。它不等同于生产使用量,但能告诉我们用户在看什么。这很有用。它能告诉我们哪些扩展值得优先投入打包精力,哪些类别正在活跃起来。
这里是过去一个月的扩展页面访问量数据。
17. 仓库#
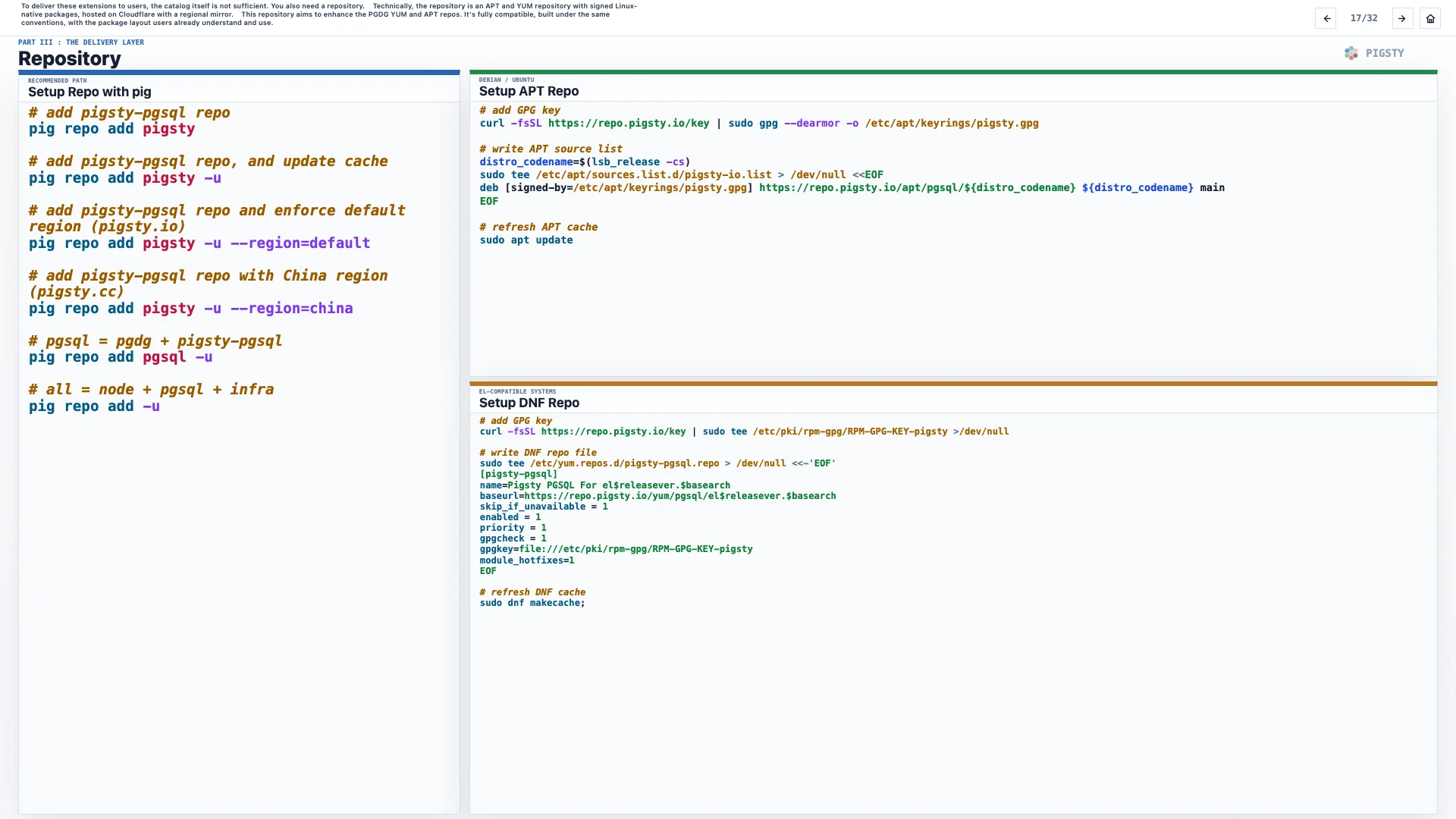
要把这些扩展交付给用户,只有目录还不够。还需要一个仓库。
从技术上说,这个仓库是一个 APT 与 YUM 仓库,提供签名的 Linux 原生包,托管在 Cloudflare 上,并带有区域镜像。
这个仓库的目标是增强 PGDG 的 YUM 和 APT 仓库。它完全兼容 PGDG,遵循同样的约定,使用用户已经理解和熟悉的包布局。
18. 仓库下载统计#
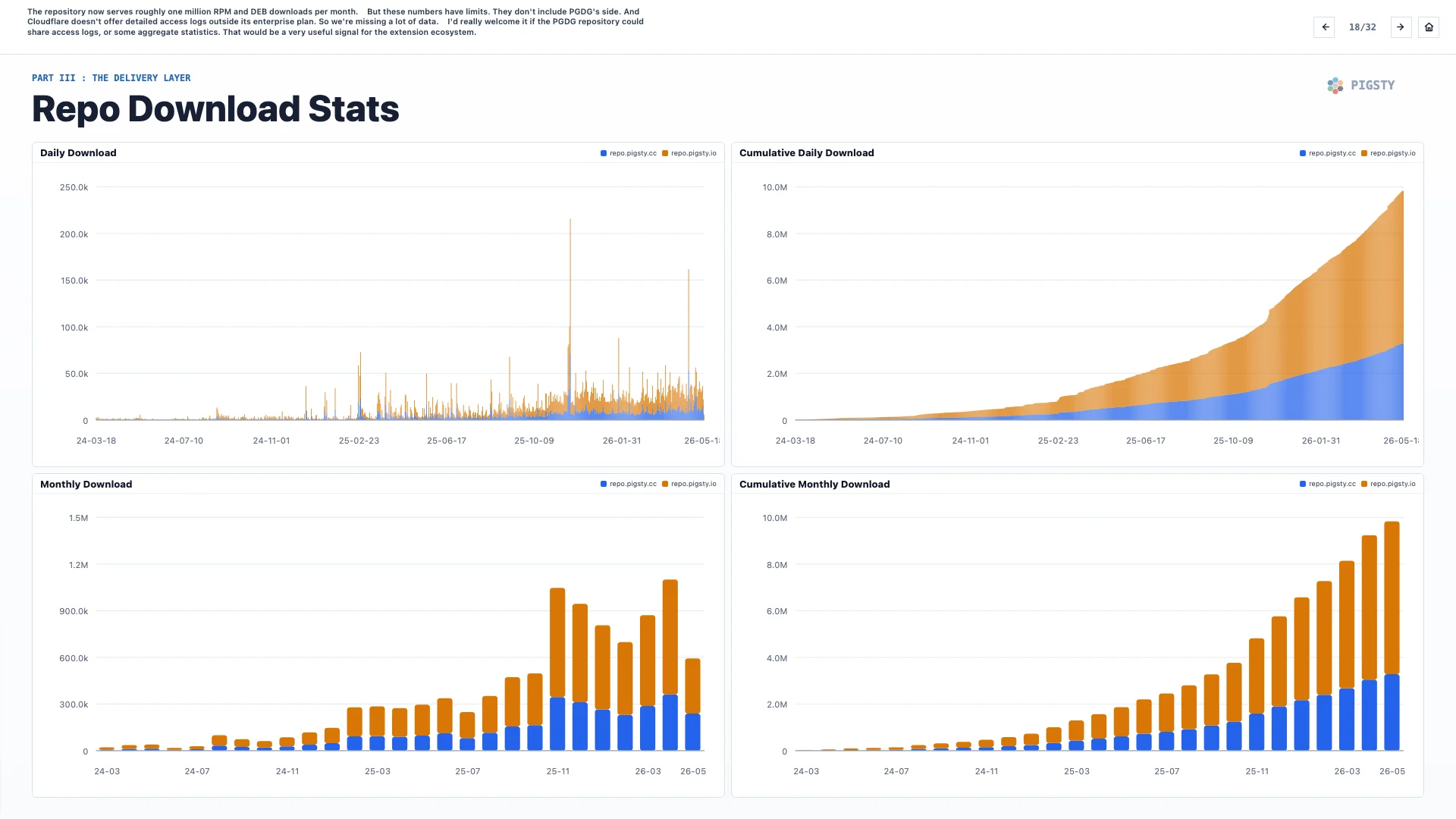
这个仓库现在每月大约提供一百万次 RPM 和 DEB 下载。
但这些数字有局限。它们不包括 PGDG 那一侧的数据。而 Cloudflare 在企业版之外不提供详细访问日志,所以我们缺失了很多数据。
如果 PGDG 仓库能够共享访问日志,或者至少提供一些聚合统计,我会非常欢迎。那会成为扩展生态里非常有价值的信号。
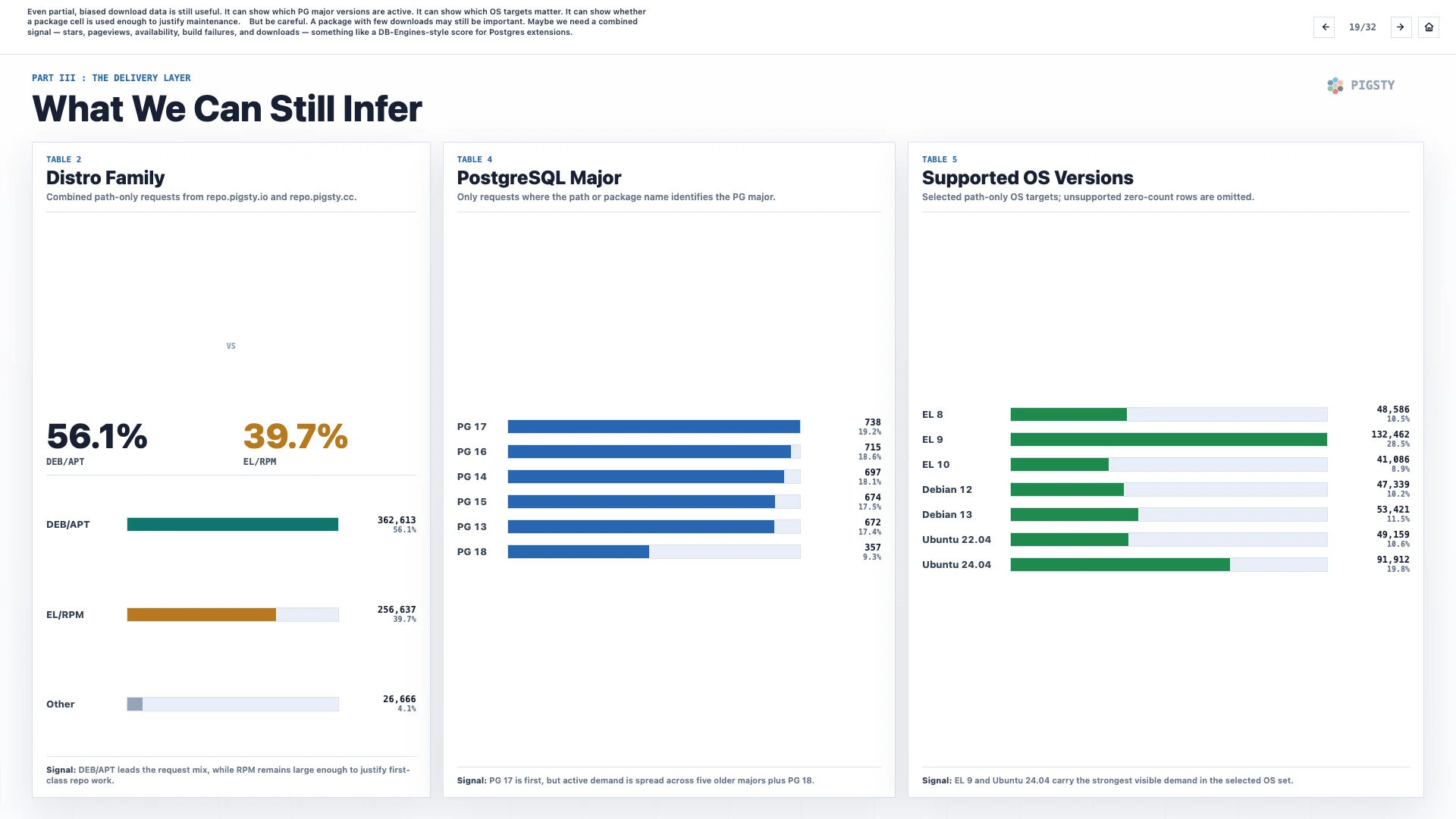
19. 我们仍然可以推断什么#
即便下载数据是局部的、有偏的,它仍然有用。它可以显示哪些 PG 大版本仍然活跃,哪些操作系统目标重要,也可以显示某个包组合是否有足够使用量,值得继续维护。
但要小心。下载量少的包仍然可能很重要。也许我们需要一个综合信号,把星标、页面访问量、可用性、构建失败和下载量结合起来,形成类似 DB-Engines 风格的 PostgreSQL 扩展评分。
20. CLI:PIG#
有了目录和仓库,扩展交付基本上就解决了。你可以直接使用系统包管理器,从 PGDG 和 PGEXT 仓库安装扩展,比如 dnf 或 apt。
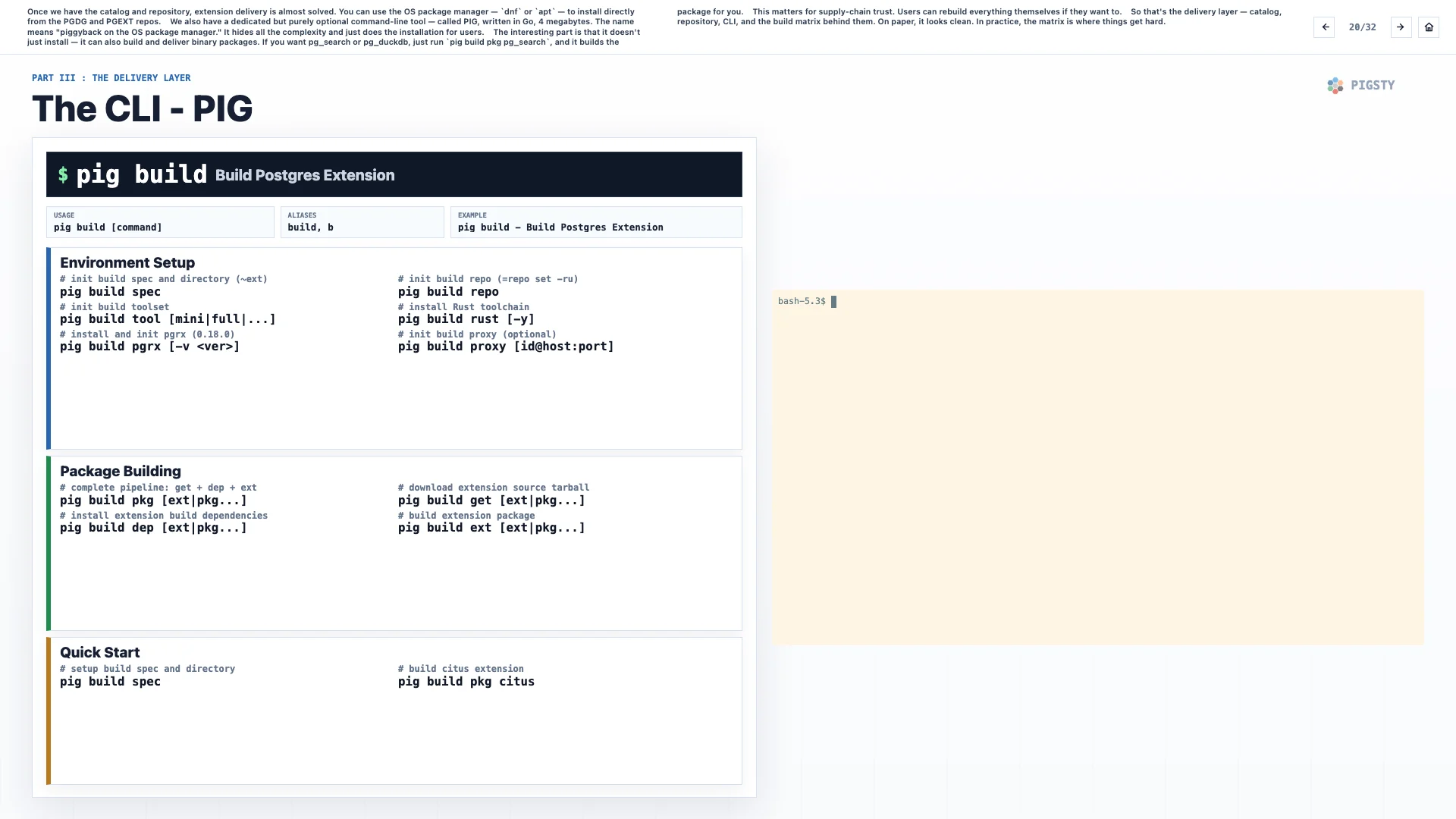
我们还有一个专用但完全可选的命令行工具,叫 PIG。它用 Go 编写,只有 4 MB。这个名字的含义是「piggyback on the OS package manager」,也就是借力系统包管理器。它会隐藏所有复杂度,让用户直接完成安装。
有意思的是,它不只是能安装,也能构建和交付二进制包。如果你想要 pg_search 或 pg_duckdb,只要运行 pig build pkg pg_search,它就会帮你构建包。
这对供应链信任很重要。用户愿意的话,可以自行重建所有东西。
这就是交付层:目录、仓库、CLI,以及它们背后的构建矩阵。纸面上看起来很清晰。但在实践中,矩阵才是真正困难的地方。
第四部分:野外维护#
21. 扩展矩阵#
上一章我们谈到了矩阵:每个扩展 80 个槽位。
但 5 个 PG 版本乘以 16 个 Linux 平台,只是一个过度简化的模型。真实情况要混乱得多。它包含的因素远不止行和列。
在操作系统侧,有发行版家族、架构、大版本,有时还有小版本。
在 PG 侧,有大版本,有时也有小版本。
在扩展侧,有扩展版本;对于 Rust 扩展,还有 pgrx 版本。
把这些因素相乘,组合数量会非常快地爆炸。
本部分接下来要讨论的,就是这种爆炸式复杂度撞上现实之后,我们学到了什么。

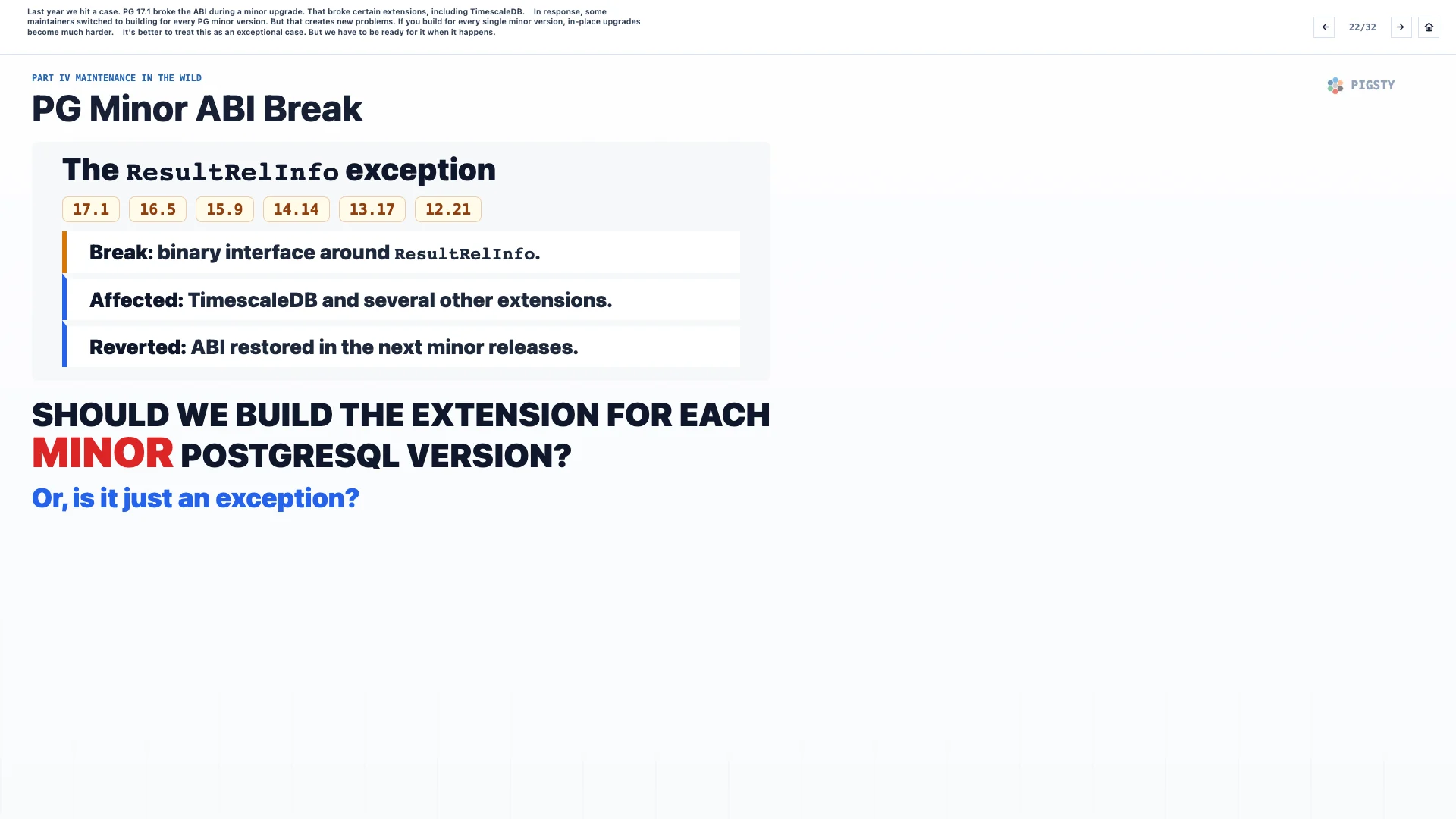
22. PG 小版本 ABI 破坏#
去年我们遇到过一个案例。PG 17.1 在小版本升级中破坏了 ABI,导致包括 TimescaleDB 在内的一些扩展出问题。
作为回应,一些维护者转向为每一个 PG 小版本构建。但这又会制造新的问题。如果每个小版本都单独构建,原地升级就会变得困难得多。
更好的办法是把它当作例外情况处理。但当它真的发生时,我们必须做好准备。
23. 操作系统小版本破坏#
有时候,即使是操作系统的小版本也会破坏构建。
例如,EL 把 OpenSSL 版本从 3.2 升到 3.5,一些扩展会在链接阶段失败。
作为回应,PGDG YUM 仓库最近修改了打包策略,从按大版本构建改为按小版本构建。所以现在我们有了 EL 10.0、10.1、9.6、9.7 的独立构建,而不只是 EL 10 和 EL 9。这又给矩阵增加了一个子维度。

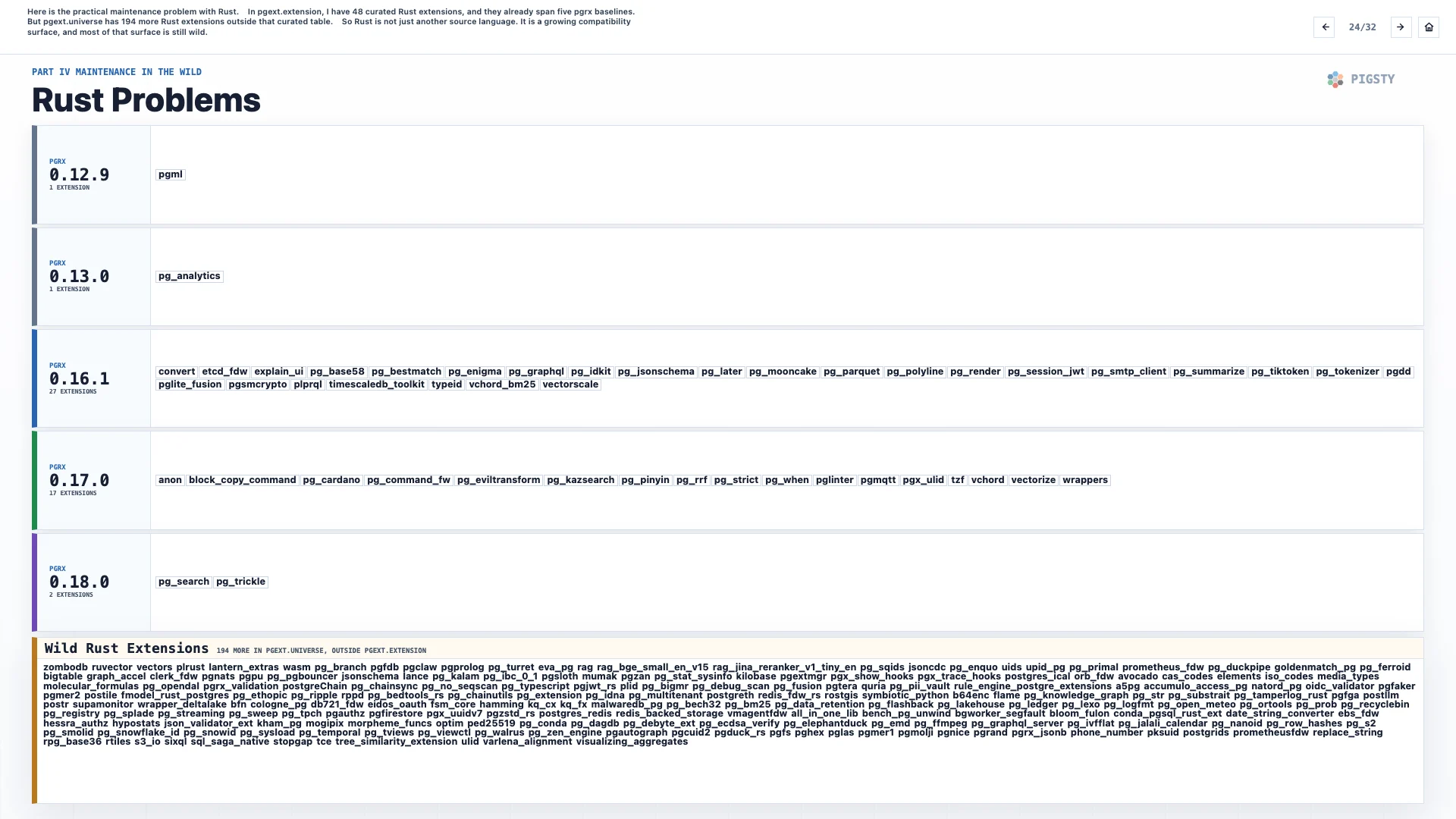
24. Rust 问题#
Rust 扩展正在增长。它们给生态带来了新的人和新的想法。Rust 社区使用一个叫 pgrx 的框架来编写这些扩展,而这又引入了几个新问题。
第一是构建成本。Rust 构建很慢,也很吃磁盘。一个 Rust 扩展的构建时间,可能比所有 C 扩展加起来还长。
第二是 pgrx 自身也有版本,比如 0.16、0.17、0.18,而且它们并不能互换。我花了很多时间把 Rust 扩展对齐到特定的 pgrx 版本上,但随着时间推移,版本漂移又会回来。
所以 Rust 不只是增加了一门语言。它还增加了一条兼容性维度。
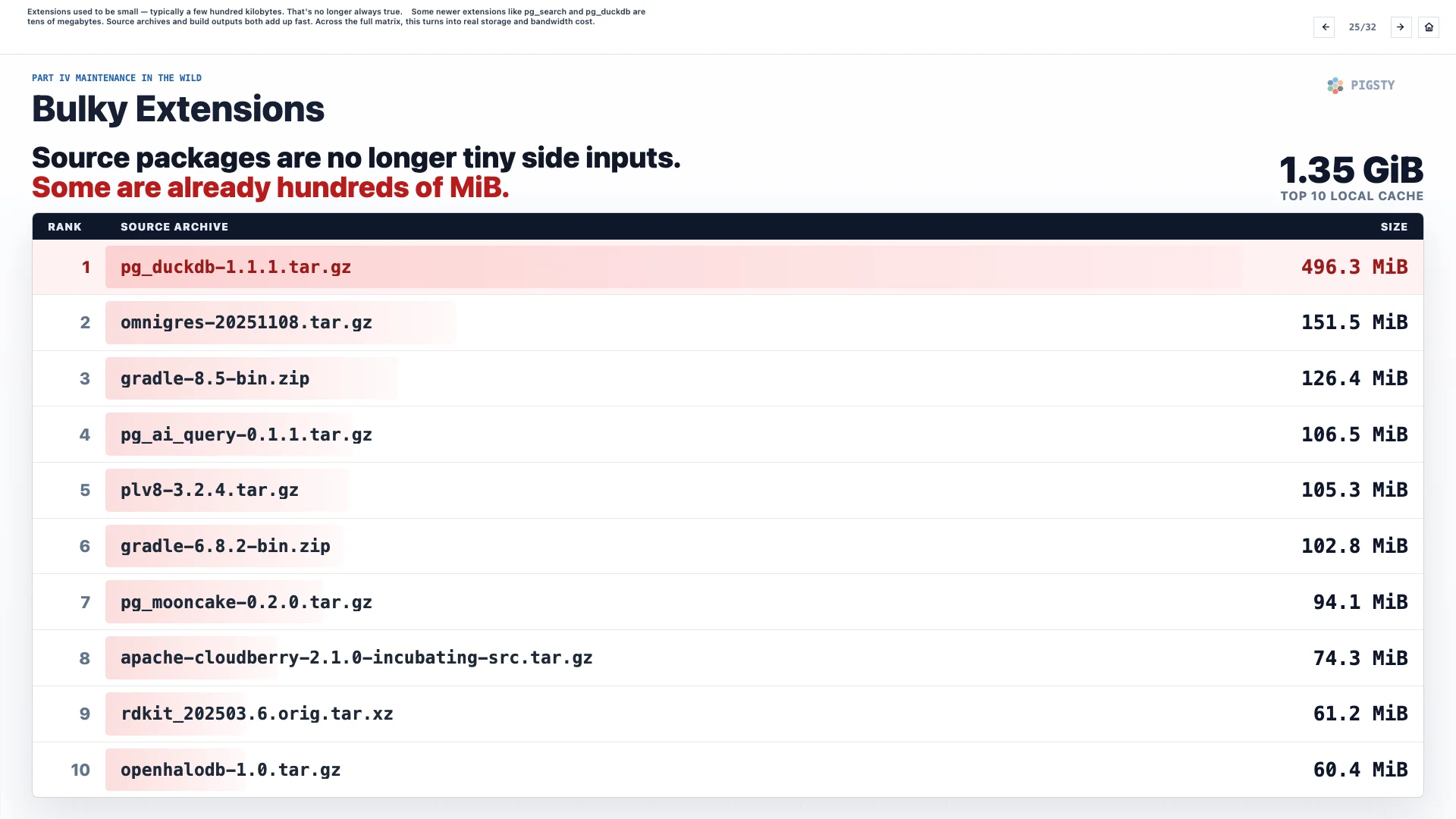
25. 臃肿的扩展#
过去扩展通常很小,典型大小只有几百 KB。现在不总是这样了。
一些新的扩展,比如 pg_search 和 pg_duckdb,体积有几十 MB。源码归档和构建产物都会迅速膨胀。放到完整矩阵里,这会变成真实的存储和带宽成本。
26. 命名冲突#
矩阵是一类复杂性,扩展之间的冲突是另一类。
去年,我讲过 Citus 和 Hydra 争夺同一个名字 columnar 的问题。今年我们又有了一个新例子:bm25。现在有三个扩展暴露了名为 bm25 的访问方法:
- ParadeDB 的 pg_search
- Timescale 的 pg_textsearch
- TensorChord 的 vchord_bm25
和 Citus 与 Hydra 不同,这三个扩展可以一起安装。但你不能在同一个数据库里把它们全都创建出来,因为访问方法名称会冲突。
这不只是一个打包问题,而是生态元数据问题。如果目录记录的不只是包名,还包括扩展对象、库和访问方法,作者就可以在发布前检查冲突。

27. 库冲突#
另一个例子是,三个基于 DuckDB 的扩展都想使用同一个共享库:libduckdb。
包管理器看到的是磁盘上的文件。PostgreSQL 看到的是共享库和 control 文件。用户看到的是 CREATE EXTENSION。这三层的理解可能互相不一致。
实际解决方案,是把其中两个扩展作为 pg_duckdb 下面的子扩展挂载起来。这个方案能工作,但协调和说服作者花了真实的精力。
教训很简单:名字也是兼容性的一部分,而且名字真的会冲突。

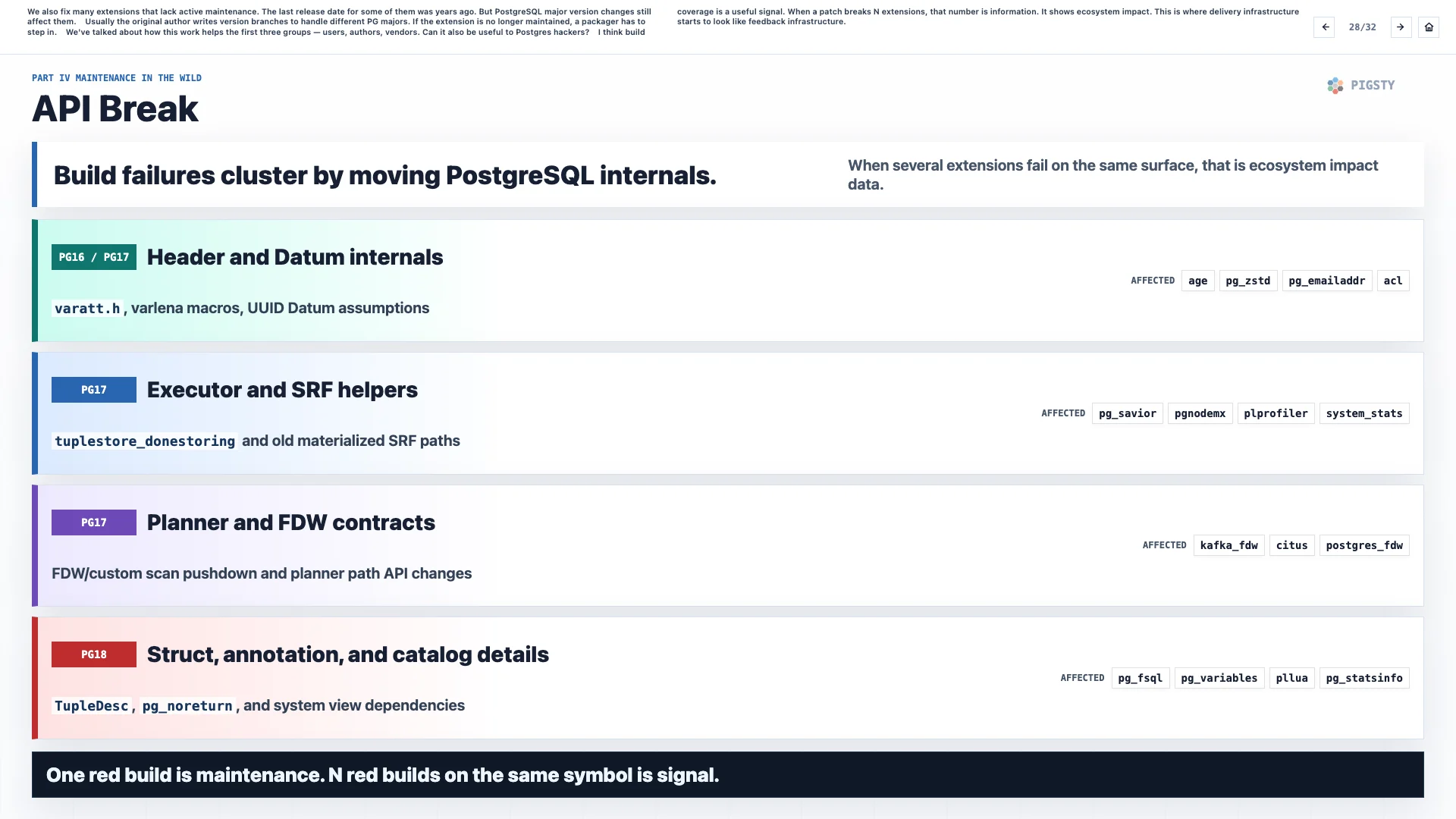
28. API 破坏#
我们也修复了很多缺乏活跃维护的扩展。有些扩展距离上一次发布已经过去多年。但 PostgreSQL 大版本变化仍然会影响它们。
通常,原作者会编写不同版本分支来处理不同 PG 大版本。如果扩展已经不再维护,打包者就必须接手。
前面我们讲过,这项工作如何帮助前三类人:用户、作者和厂商。那它对 PostgreSQL 内核开发者是否也有用?
我认为,构建覆盖率是一种有用信号。当一个补丁破坏了 N 个扩展时,这个数字本身就是信息。它显示了生态影响。这时,交付基础设施就开始变成反馈基础设施。
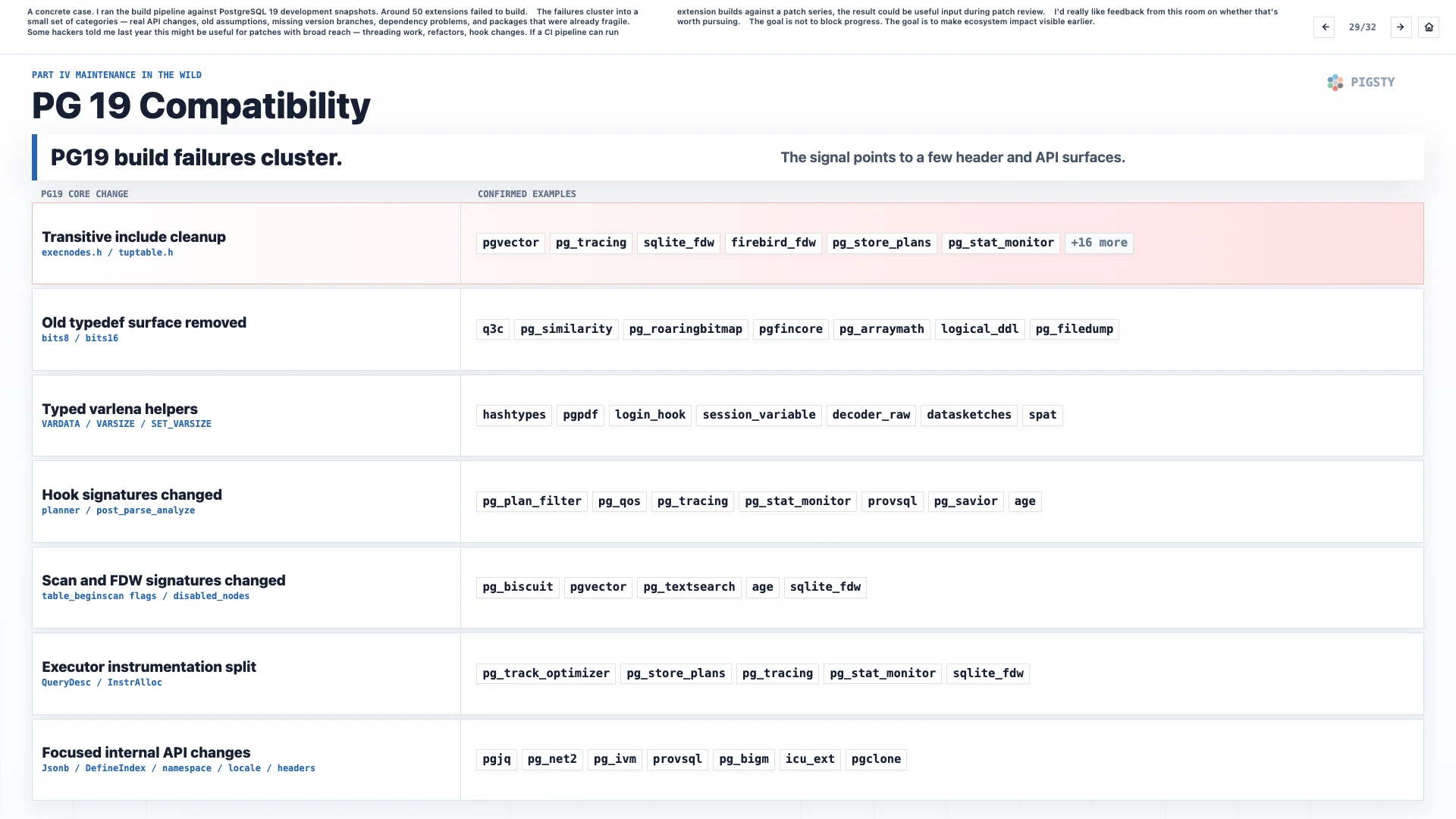
29. PG 19 兼容性#
一个具体案例是,我用 PostgreSQL 19 的开发快照跑了一遍构建流水线。大约 50 个扩展构建失败。
这些失败集中在少数几类:真正的 API 变化、过时的假设、缺少版本分支、依赖问题,以及原本就已经很脆弱的包。
去年有些内核开发者告诉我,这对影响面很广的补丁可能有用,比如线程化工作、重构、hook 变化。如果 CI 流水线能针对某个补丁系列运行扩展构建,那么结果就可以成为补丁评审过程中的有用输入。
我很想听听在座各位的反馈:这件事值不值得继续推进?目标是让生态影响更早可见。
30. 让它可维护#
一个现实问题是可维护性。所有这些工作都是一个人在做。我经营着一家一人公司,也维护着一个一人发行版 Pigsty。这件事我已经做了大约五年。
最近它变得容易了一些,原因是 AI 工具。去年,每一个构建 spec 都是手写的。积累了足够多的示例之后,添加新扩展已经变得很直接。上个月我在两天内新增了 50 个扩展。
我的朋友 Yurii Rashkovskii 曾经描述过一个叫 PGPM 的想法:URL in, RPM out。给一个 URL,吐出一个 RPM。有了 Codex 和 Claude Code,这个想法正在变成现实。
AI 也降低了测试成本。我们可以从扩展文档驱动冒烟检查,更早捕获行为回归。AI 可能还没准备好提交 Postgres 内核补丁。但它显然足够胜任这类工作。我维护了一个 MinIO 分叉,用来修复 CVE 和 bug,几乎完全依靠 Codex 和 Claude Code。它真的跑在生产环境里。
这是一个维护者让 511 个扩展组成的矩阵继续活下去的办法。

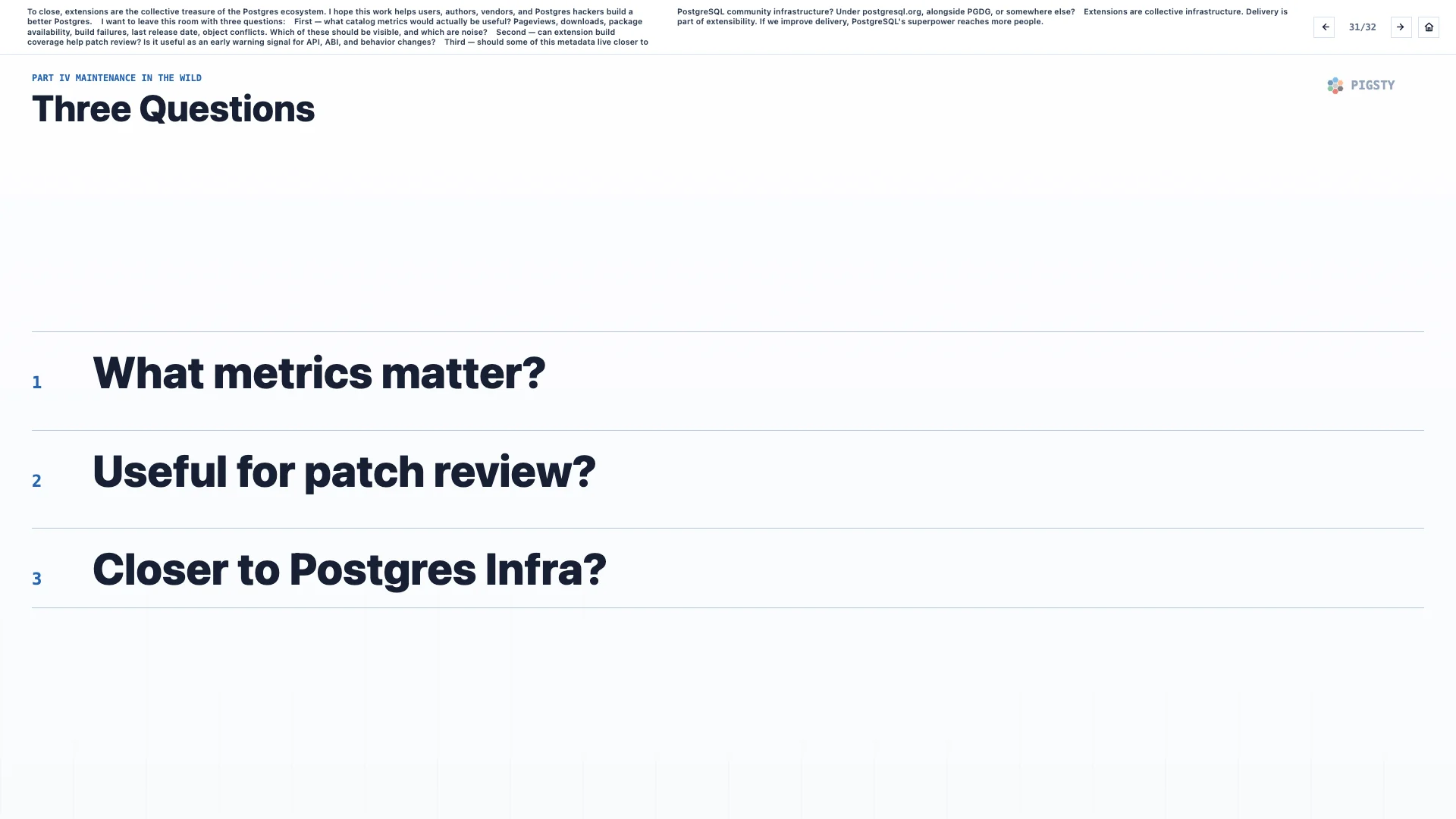
31. 三个问题#
最后,扩展是 Postgres 生态的共同财富。我希望这项工作能帮助用户、作者、厂商和 Postgres 内核开发者,一起建设更好的 Postgres。
我想带着三个问题离开这个房间:
第一,哪些目录指标真正有用?页面访问量、下载量、包可用性、构建失败、最近发布日期、对象冲突。哪些应该被公开展示,哪些只是噪音?
第二,扩展构建覆盖率能否帮助补丁评审?它是否能作为 API、ABI 和行为变化的早期预警信号?
第三,其中一些元数据是否应该更靠近 PostgreSQL 社区基础设施?放在 postgresql.org 下,和 PGDG 放在一起,还是放在别的地方?
扩展是共同基础设施。交付是可扩展性的一部分。如果我们改善交付,PostgreSQL 的超能力就能触达更多人。
32. 致谢#
谢谢大家。
如果有任何问题,欢迎联系我。