


After over a year of iterations and refinement, Pigsty officially ships v1.0.0 GA.
Pigsty (/ˈpɪɡˌstaɪ/) stands for PostgreSQL In Graphic STYle — PostgreSQL, visualized.
What is Pigsty?#
Pigsty is a batteries-included PostgreSQL distribution that bundles production-grade cluster deployment, scaling, replication, failover, traffic routing, connection pooling, service discovery, access control, monitoring, alerting, and logging into a single cohesive package. It solves the hard problems you’ll face when running PostgreSQL — the world’s most advanced open-source relational database — in production.
| Role | Description |
|---|---|
| Distribution | Batteries-included PostgreSQL distribution |
| Monitoring | Professional-grade PostgreSQL observability |
| Deployment | Simple, HA-ready deployment solution |
| Sandbox | Versatile local sandbox & data visualization environment |
| Open Source | Free as in freedom, Apache 2.0 licensed |
Core Features#



Distribution#
A distribution is a complete solution built from a database kernel plus a curated set of software packages. Linux is an OS kernel; RedHat, Debian, and SUSE are distributions built on top of it. PostgreSQL is a database kernel; Pigsty, BigSQL, Percona, and various cloud RDS offerings are distributions built on top of it.

As a database distribution, Pigsty’s core strengths are:
- Comprehensive, professional monitoring system
- Simple, easy-to-use deployment solution
- Stable, reliable high-availability architecture
- Versatile, powerful sandbox environment
- Free, friendly open-source license
Batteries Included#
Batteries-included means: start with a fresh VM, run one command, and within 10 minutes you’ll have infrastructure, database, monitoring, and control plane fully operational.
Pigsty pushes deployment and monitoring to the extreme, turning the historically high-barrier work of deploying, managing, and operating large-scale database clusters into something any developer can handle.
For power users, Pigsty provides the most comprehensive monitoring system available. For everyone else, Pigsty provides the simplest deployment experience. For data engineers, Pigsty also integrates tools like JupyterLab and ECharts, making it a complete IDE for data development and visualization.
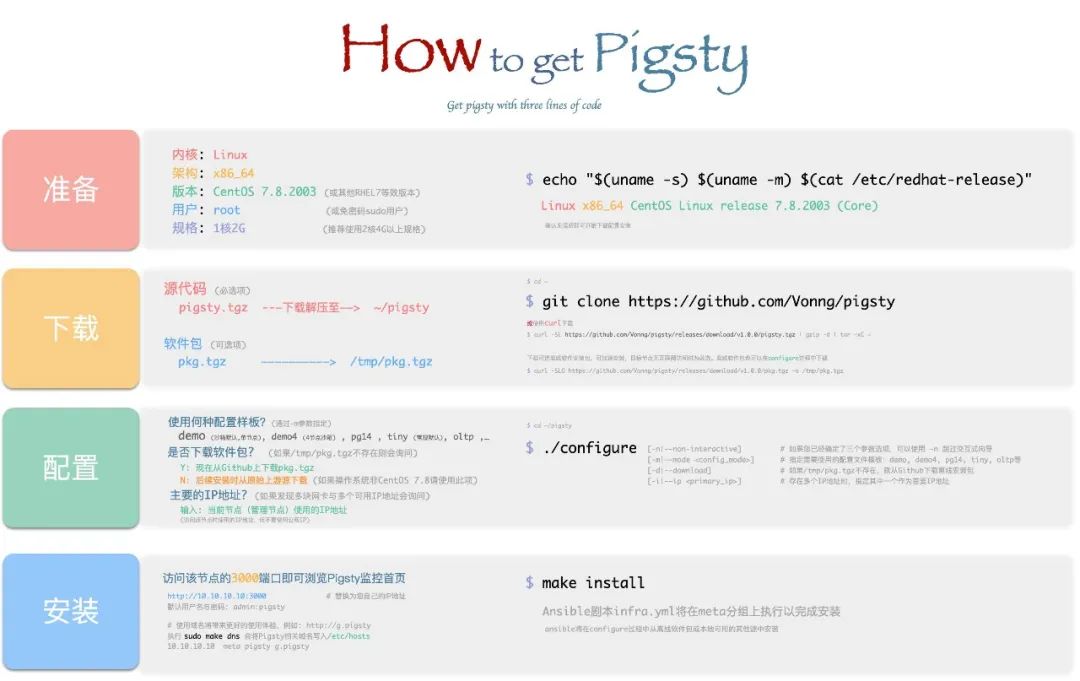
Monitoring System#
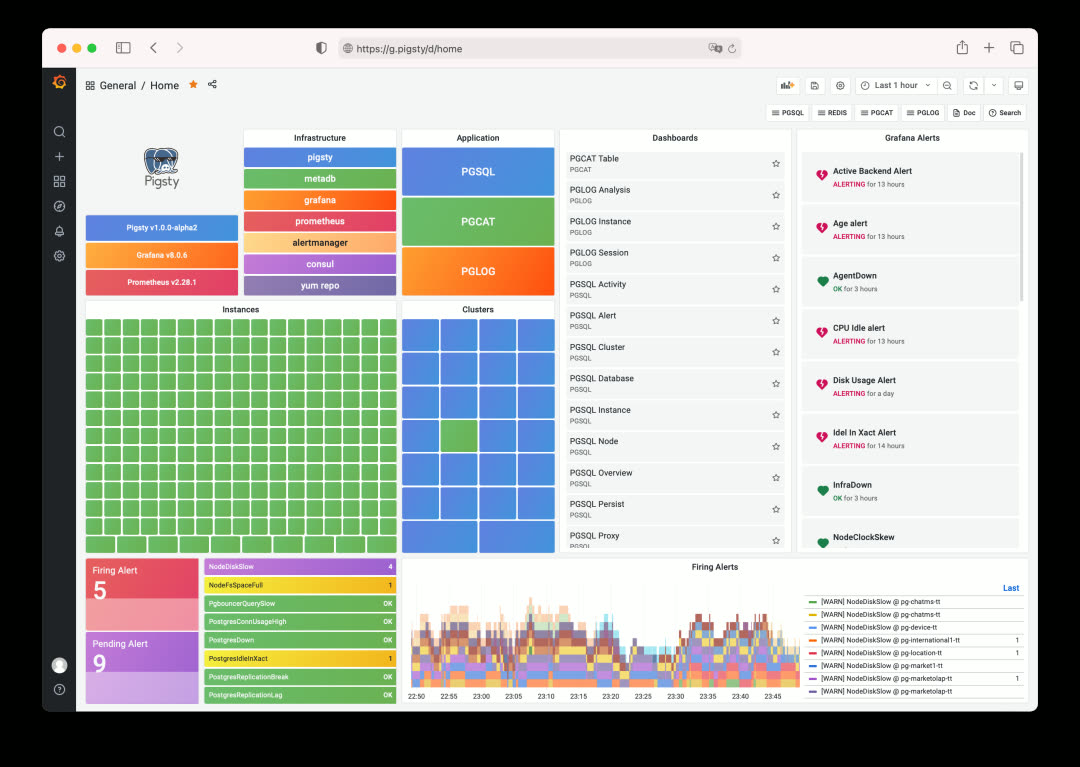
Pigsty ships with a professional-grade PostgreSQL monitoring system designed for large-scale database fleet management. It includes ~1200 metric types, 20+ dashboards, and thousands of panels, covering everything from fleet-wide overviews down to individual object details. Compared to alternatives, it leads by a wide margin in metric coverage and dashboard richness — delivering irreplaceable value for professionals.
A typical Pigsty deployment can manage hundreds of database clusters, collect thousands of metric types, handle millions of time series, and organize them into thousands of panels across dozens of dashboards in real-time. From global fleet overviews to per-object details (tables, queries, indexes, functions), it’s like having a real-time MRI/CT scanner for your database — everything laid bare.

Dashboard gallery
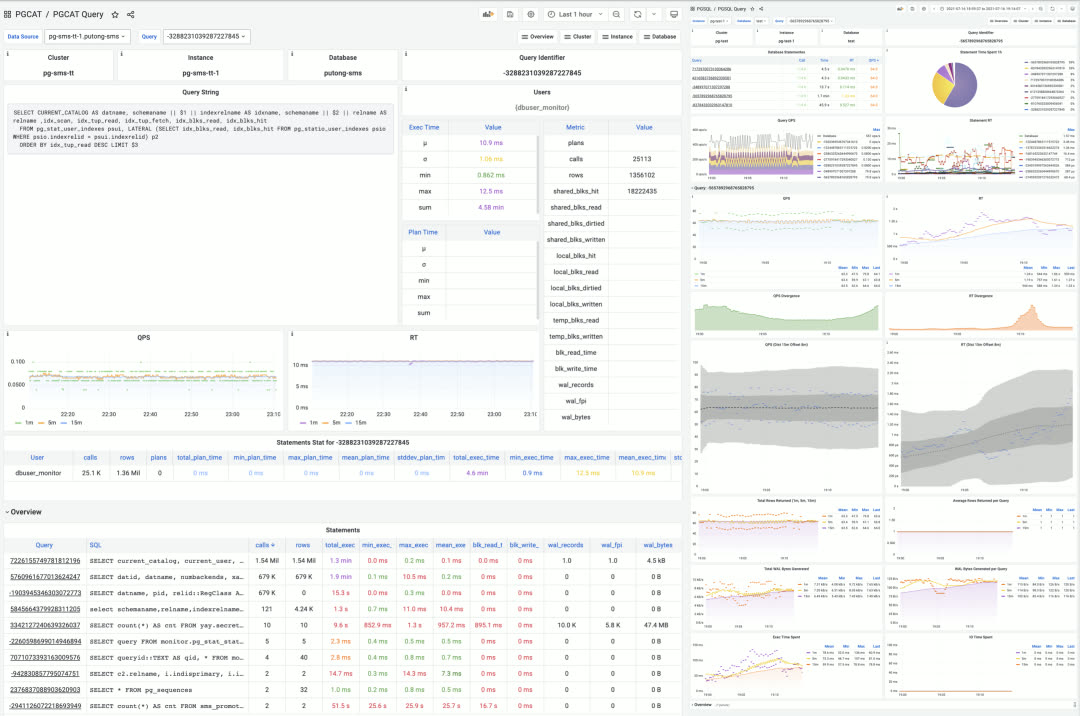
Single query monitoring
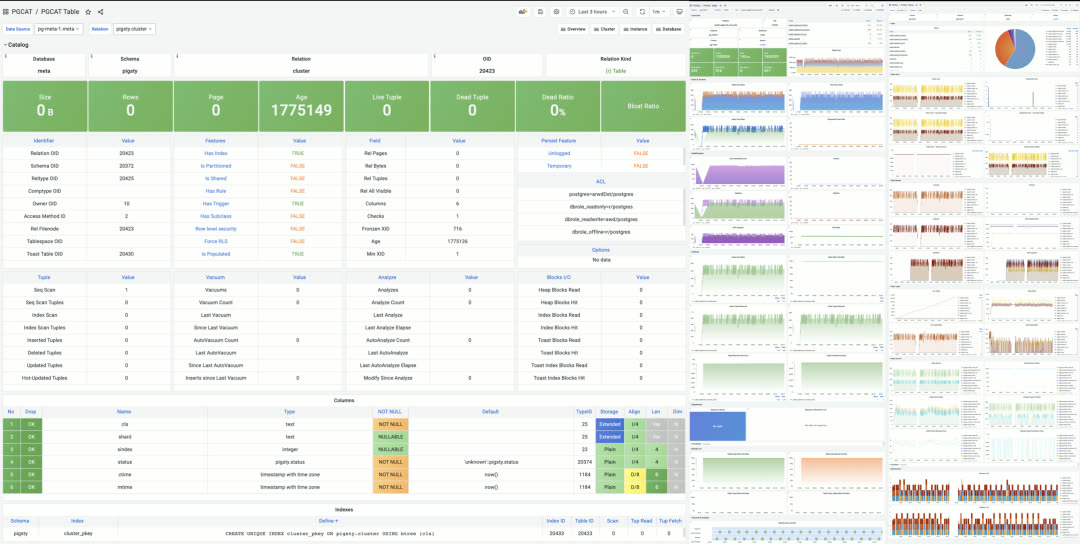
Single table monitoring

Instance-level monitoring dashboard
Three Core Applications#
Pigsty’s monitoring system is composed of three tightly integrated core applications:
PGSQL — Collect and visualize monitoring metrics
PGCAT — Browse database system catalogs directly
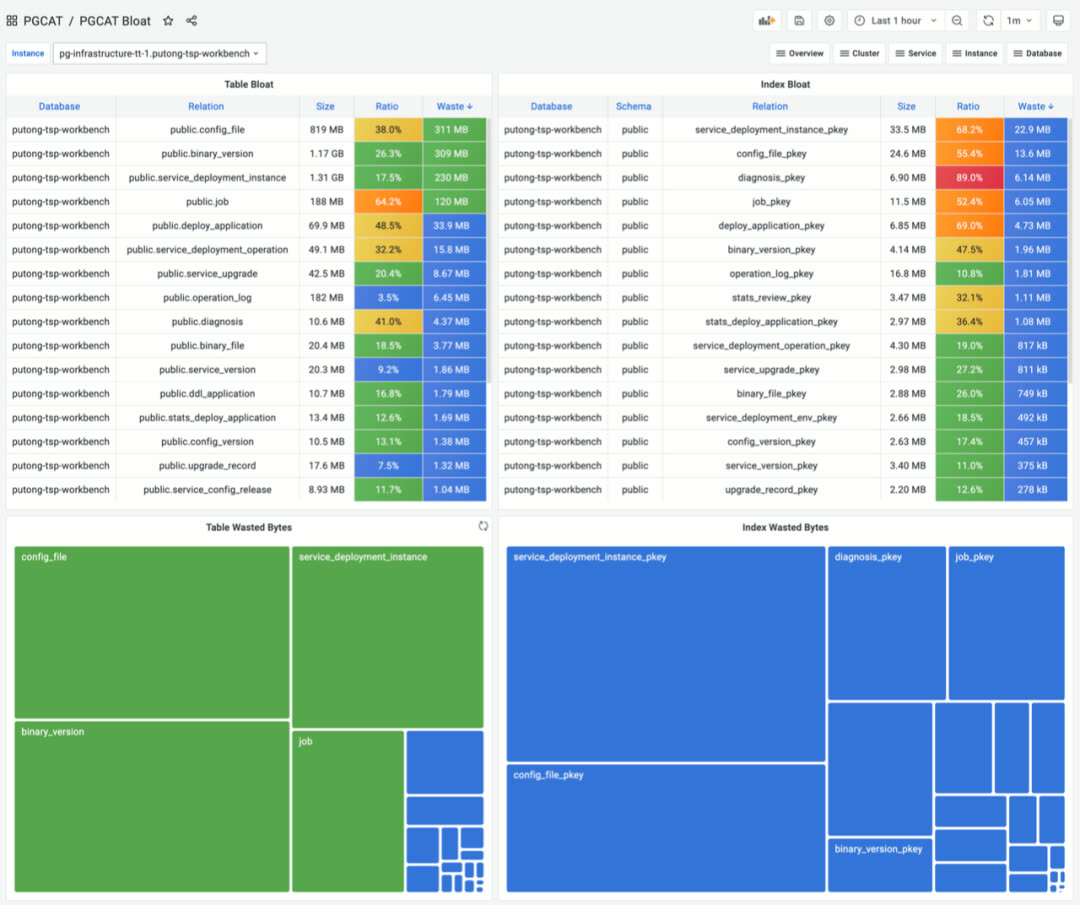
PGLOG — Real-time log search and analysis
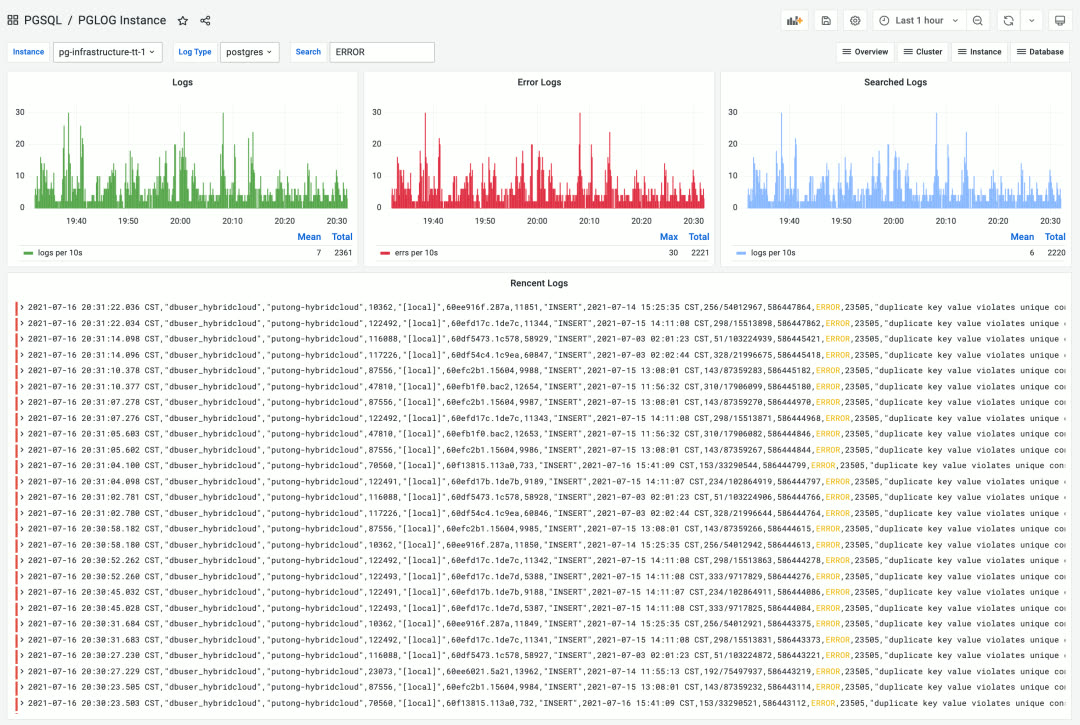
Pigsty’s monitoring system is built on industry best practices, using Prometheus and Grafana as the monitoring infrastructure. Open source, easy to customize, reusable, portable, no vendor lock-in. It can integrate with existing PostgreSQL instances and can also be used to monitor and manage other databases or applications (like Redis).
Deployment Solution#
A database is software that manages data. A control plane is software that manages databases.
Pigsty includes an Ansible-based database management solution, with CLI and GUI wrappers on top. It handles core database management functions: cluster creation, destruction, scaling; user, database, and service provisioning.
Pigsty embraces the Infrastructure as Code philosophy, using Kubernetes-style declarative configuration. Describe your database and runtime environment through extensive config options, and idempotent playbooks automatically create the clusters you need — delivering a private-cloud-like experience.
Users simply describe “what kind of database they want” via config files or GUI — no need to worry about how Pigsty creates or modifies it. Pigsty will spin up the desired database cluster from bare metal nodes within minutes.

For users who prefer not to work with config files and Ansible playbooks, Pigsty also offers optional CMDB mode and CLI/GUI tools wrapping common operations.
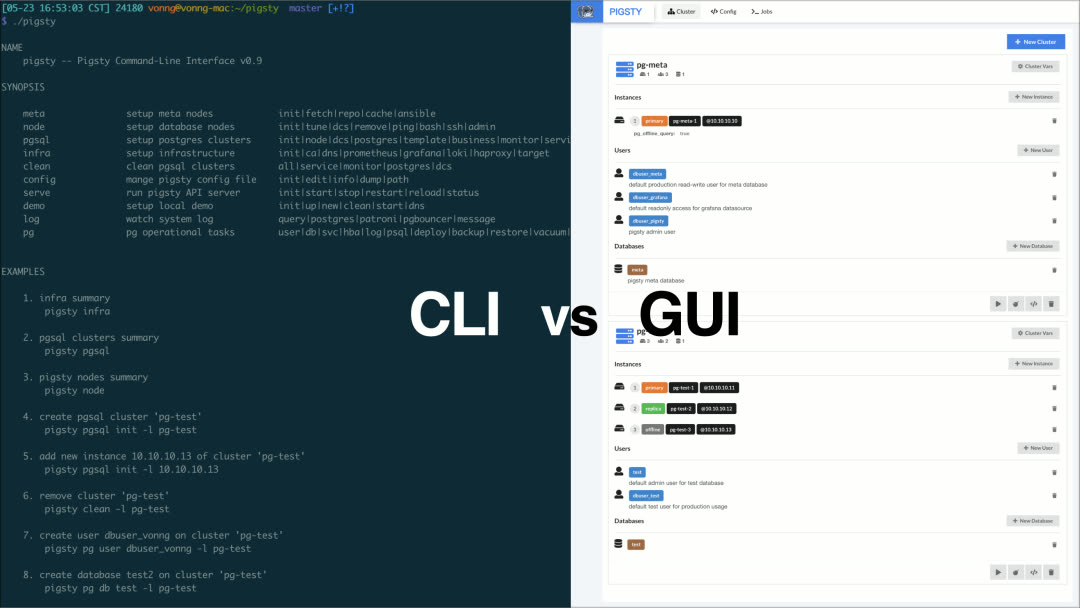
For power users, Pigsty provides 160+ configurable parameters, allowing fine-grained control over every aspect of cluster and infrastructure runtime. Beginners can create reliable database clusters without changing a single config setting.
High Availability Clusters#
Pigsty creates distributed, highly-available database clusters. In practice, as long as any instance in the cluster survives, the cluster can provide full read-write and read-only services.
Every database instance in the cluster is functionally equivalent — any instance can serve full read-write traffic through the built-in load balancer. Clusters automatically detect failures and perform primary-replica failover; typical failures self-heal in seconds to tens of seconds, with read-only traffic unaffected during the process.
Pigsty’s HA architecture is battle-tested in production, achieving complete high availability with minimal complexity — making traditional primary-replica databases feel like distributed databases.
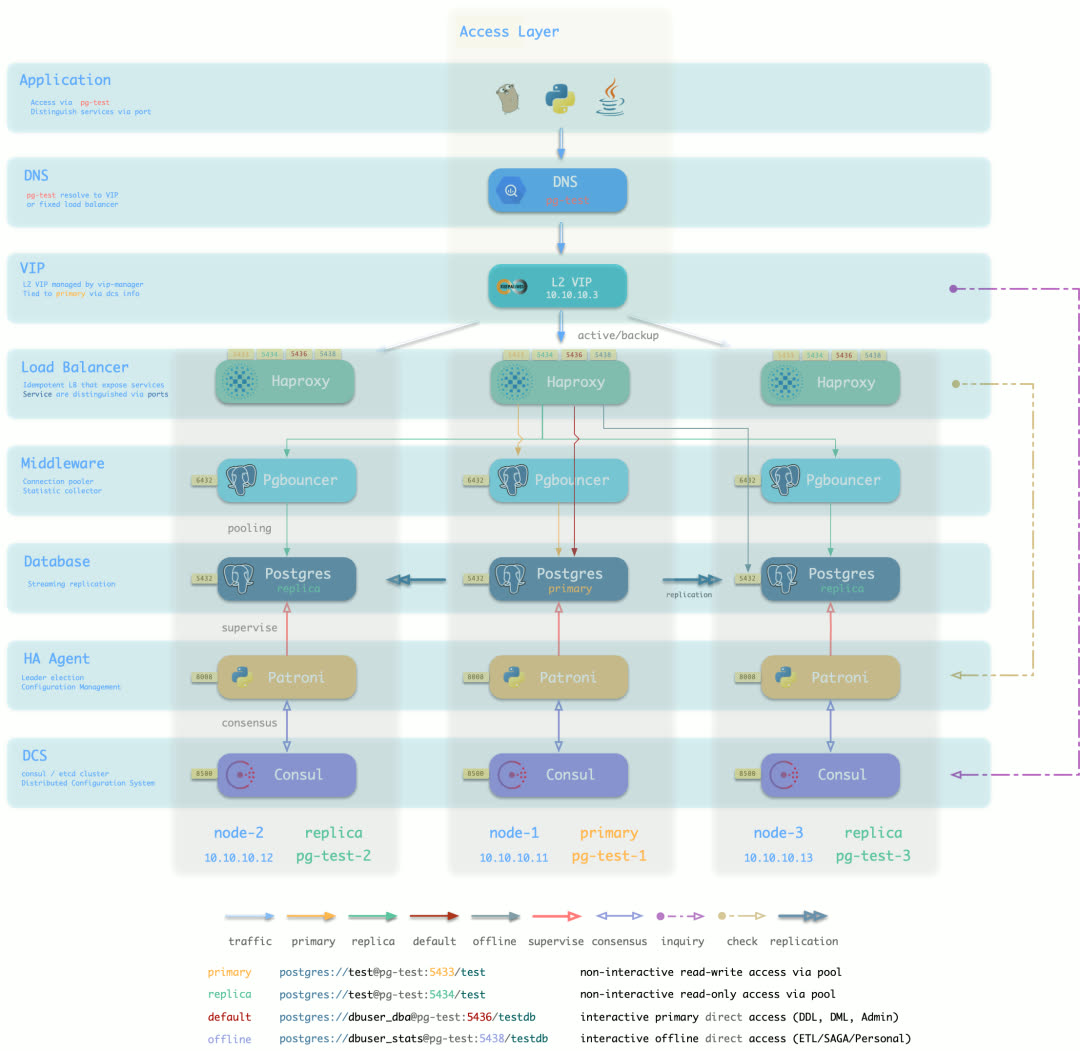
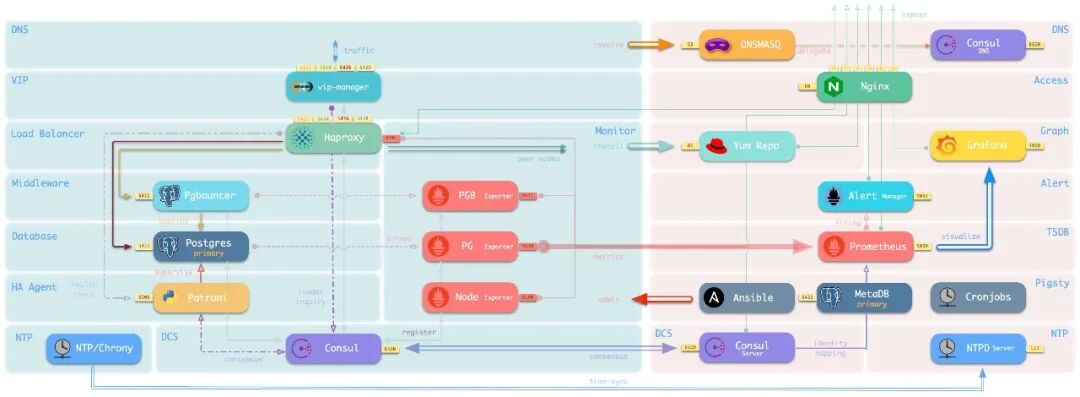
Default access topology (DNS + L2 VIP + HAProxy, 7 options total)
Sandbox Environment#
PostgreSQL users aren’t just enterprises — countless individuals use it for software development, testing, experiments, demos, or for data cleaning, analysis, visualization, and storage. Setting up the environment is often the first hurdle.
The Pigsty sandbox solves this problem. With one click, spin up a complete production-grade PostgreSQL service on your laptop or PC (Vagrant calls VirtualBox to automatically create the VMs). The default sandbox is single-node (2c/4g) with all essential tools, suitable for various use cases. There’s also a four-node full sandbox for production-like environments, fully exploring Pigsty’s HA architecture and monitoring capabilities.
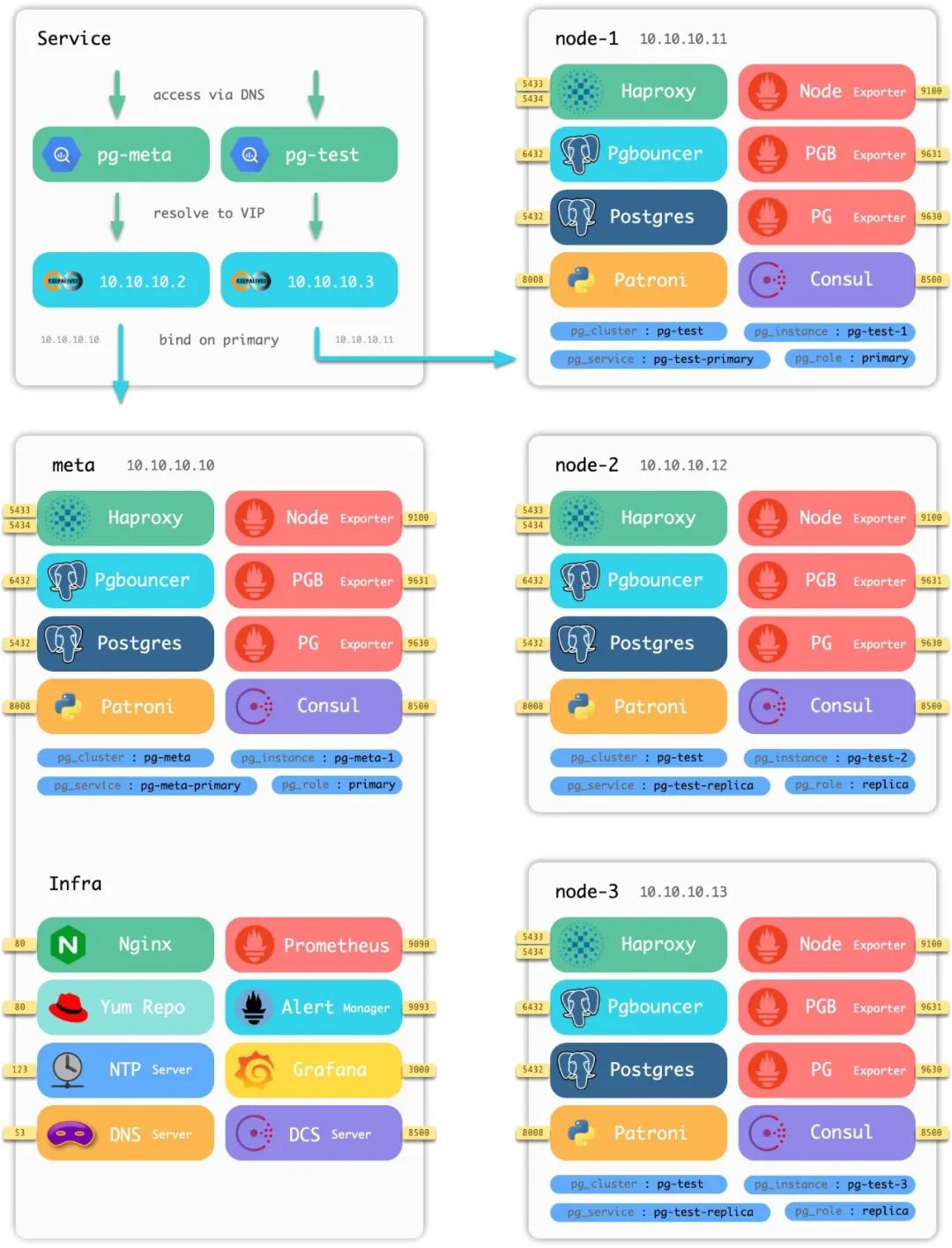
Four-node sandbox architecture diagram
Data Analysis#
Pigsty provides PostgreSQL as the backend database, JupyterLab as the Python IDE, Grafana as the frontend/backend runtime, and the Grafana ECharts Panel for advanced visualization. Together, these tools form a complete toolkit for data processing, analysis, and data application development.
Build your data analysis workflow on Pigsty, rapidly prototype data application POCs, and package/distribute/deploy them in a standardized way. Pigsty ships with two sample data applications:
COVID — Pandemic data visualization app
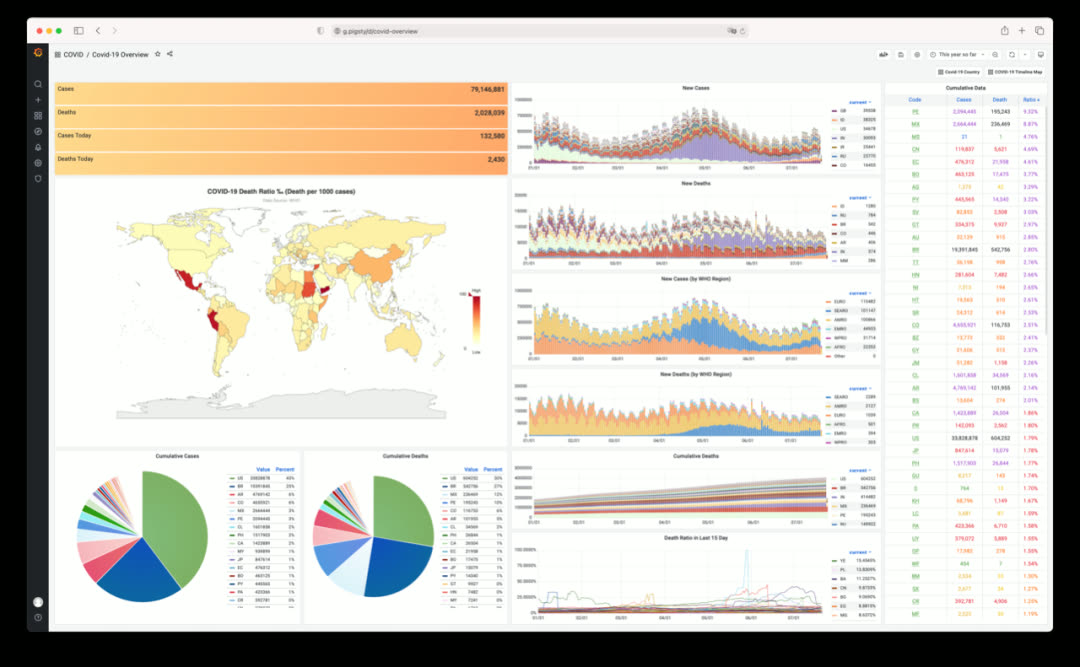
Click to view individual country details and timeline maps
ISD — Global surface weather station historical data explorer
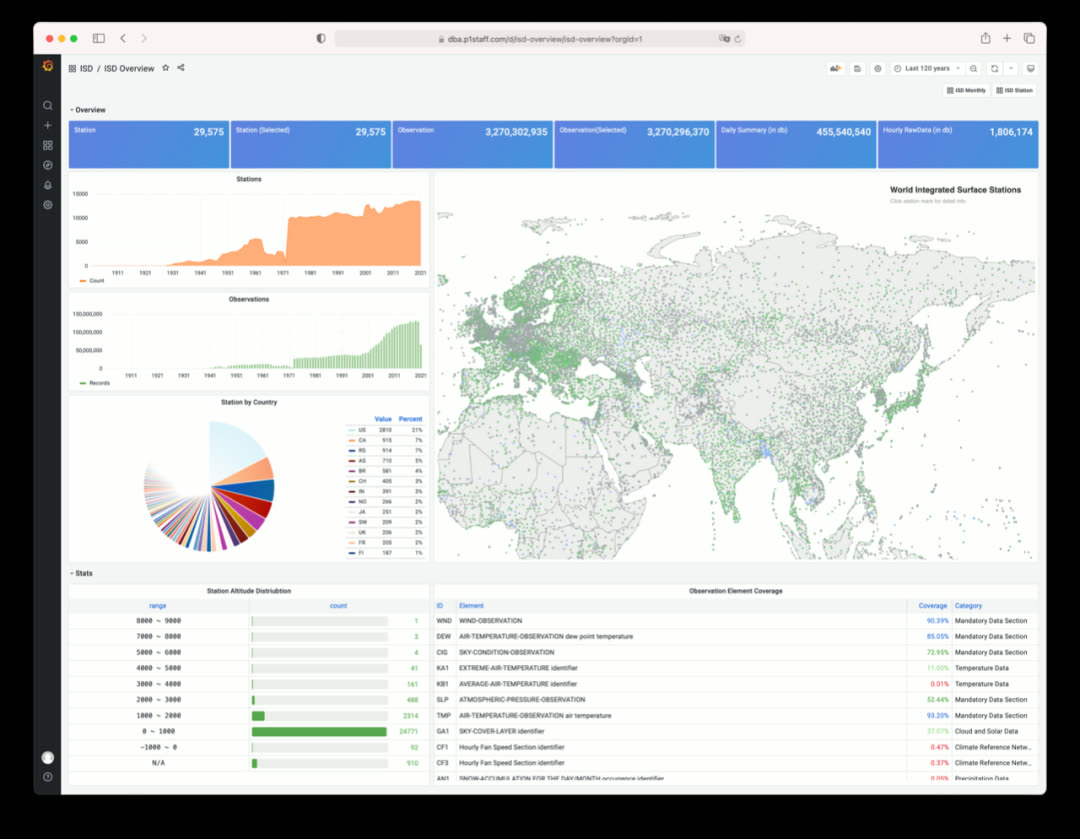
Click to view individual station details and historical weather data
Roadmap#


Open Source#
Pigsty is open-source under the Apache 2.0 license — free for commercial use, with modifications and derivatives subject to Apache License 2.0’s attribution requirements.
Pigsty’s mission: Use databases well, use good databases.
Give SMBs a truly self-controlled choice, and let everyone enjoy the power of PostgreSQL.
v1.0.0 Release Notes#
Monitoring System Overhaul
- New dashboards on Grafana 8.0
- New metric definitions, added PG14 support
- Simplified labeling system: static label set (job, cls, ins)
- New alerting rules and derived metrics
- Monitor multiple databases simultaneously
- Real-time log search & csvlog analysis
- Richly-linked dashboards, click through for drill-down/roll-up
Architecture Changes
- Added Citus and TimescaleDB to default installation
- Added PostgreSQL 14beta2 support
- Simplified HAProxy admin page indexing
- Decoupled infrastructure and PGSQL by adding new role
register - Added new roles
lokiandpromtailfor logging - Added new role
environto setup environment for admin user on meta node - Default to
staticservice discovery for Prometheus (instead ofconsul) - Added new role
removefor graceful cluster and instance removal - Upgraded Prometheus and Grafana provisioning logic
- Upgraded to vip-manager 1.0, node_exporter 1.2, pg_exporter 0.4, Grafana 8.0
- Every database on every instance auto-registers as a Grafana datasource
- Moved Consul registration to
registerrole, changed Consul service tags - Added cmdb.sql as pg-meta baseline definition (CMDB & PGLOG)
Application Framework
- Extensible framework for new features
- Core app: PostgreSQL monitoring system
pgsql - Core app: PostgreSQL catalog explorer
pgcat - Core app: PostgreSQL csvlog analyzer
pglog - Added sample app
covidfor COVID-19 data visualization - Added sample app
isdfor ISD weather data visualization
Other
- Added JupyterLab for full Python data science environment
- Added
vonng-echarts-panelto restore ECharts support - Added wrapper scripts
createpg,createdb,createuser - Added CMDB dynamic inventory scripts:
load_conf.py,inventory_cmdb,inventory_conf - Removed obsolete playbooks:
pgsql-monitor,pgsql-service,node-remove, etc.
API Changes
- New variable:
node_meta_pip_install - New variable:
grafana_admin_username - New variable:
grafana_database - New variable:
grafana_pgurl - New variable:
pg_shared_libraries - New variable:
pg_exporter_auto_discovery - New variable:
pg_exporter_exclude_database - New variable:
pg_exporter_include_database - Variable renamed:
grafana_url→grafana_endpoint
Bug Fixes
- Fixed default timezone Asia/Shanghai (CST) issue
- Fixed nofile limits for pgbouncer & patroni
- pgbouncer user list and database list now generated when running tag
pgbouncer
v1.0.1 Release Notes#
2021-09-14
Documentation Update
- Chinese documentation now available
- Machine-translated English documentation now available
Bug Fixes
pgsql-removeno longer removes primary instances- Replaced pg_instance with pg_cluster + pg_seq (Start-At-Task could fail when pg_instance undefined)
- Removed Citus from default shared preload libraries (Citus forces max_prepared_transaction to non-zero)
- Added ssh sudo check in
configure(now usesssh -t sudo -n lsfor permission check) - Fixed
pg-backupscript typo
Optimizations
- Removed NTP sanity check alert (duplicate of ClockSkew)
- Removed collector.systemd to reduce overhead





