I saw someone say the other day: “The point of life is to predict the future.”
That sounds plausible at first, but I think it gets the direction backwards. Prediction is not the goal. Staying alive is. So the better statement is: we stay alive by predicting the future.
This is not motivational fluff. There is a serious scientific theory behind it: the Free Energy Principle (FEP), proposed by neuroscientist Karl Friston. It is an unusually ambitious theory. The claim is that one mathematical framework may be able to explain perception, learning, decision-making, action, emotion, consciousness, and perhaps intelligence itself.
Today another friend also wrote a piece about “intelligence”, which reminded me of this framework. So this post is about the free energy principle, and why it matters if you want to understand AI, agents, and the larger ecosystem of intelligent systems we are now building.
1. What It Says#
Why Aren’t You Dead?#
This is not an insult. It is a serious physics question.
The second law of thermodynamics says that entropy in a closed system increases. Everything drifts toward disorder. A cup of hot water cools down. A house left alone decays. A system that does nothing eventually falls apart.
And yet here you are: a highly ordered system made of tens of trillions of cells, maintaining stable structure for decades. Your body temperature stays around 37 degrees C. Blood glucose stays within a narrow range. Heartbeat, breathing, hormone regulation: all coordinated, all ongoing. You are a dissipative structure, far from thermodynamic equilibrium. Your continued existence is itself something that needs to be explained.
So the question is: what kind of system can remain thermodynamically stable over time without disintegrating?
Friston’s answer is: such a system must maintain an internal model of the external world, and it must continually minimize its own variational free energy.
What Is Free Energy?#
Let’s skip the equations for a moment. The formal definition is in the appendix.
Imagine you are walking down a familiar street and a dark shape suddenly darts across the road. You flinch. That is surprise. Then you look more carefully and realize it is just a cat. Your brain updates “unknown dark object” to “cat,” the surprise disappears, and you move on.
That is free-energy minimization in miniature.
Free energy measures the mismatch between the world your model expects and the signals the world actually gives you. High free energy means reality keeps violating your predictions. Low free energy means your model is tracking the world reasonably well.
Friston’s core claim is stronger than “this is a useful strategy.” It is this: any self-organizing system that persists over time will, mathematically, behave as if it is minimizing free energy. This is not merely a strategy evolution happened to settle on. It is closer to a necessity. If a system is still around, then it must already be doing something equivalent to this. Otherwise it would have fallen apart.
A fish has to remain in water. Human body temperature has to stay within a viable range. Move too far outside those states and the system breaks down. In the language of FEP, life must keep itself inside a low-surprise region of state space.
Two Ways to Minimize Free Energy#
There are only two ways to push free energy down.
Path 1: update your beliefs. Perception and learning.
The world gives you an unexpected signal, so you revise your internal model to fit it. “That dark shape is a cat.” At short timescales, this is perception. At longer timescales, this is learning.
Path 2: change the world. Action and control.
Instead of changing your beliefs, you act so that reality matches your model. You expect to be fed, but right now you are hungry. That mismatch produces high free energy. So you go find food. Friston calls this active inference.
Taken together, these two paths unify perception and action. Traditional cognitive science often studies perception and motor control as separate systems. FEP says they are simply two solutions to the same optimization problem. The brain is not cleanly separating “understand the world” from “change the world.” It is continuously minimizing free energy.
One-line summary: life is a process that preserves itself by continually predicting and reducing surprise. Prediction is the tool. Surprise reduction is the mechanism. Staying alive is the result.
Predictive Coding: A Plausible Implementation in the Brain#
FEP is the abstract principle. Predictive coding is one concrete story for how the brain might implement it.
The cortex is hierarchical. Each level does roughly the same thing. Higher levels send predictions downward: “this is what I expect you to see next.” Lower levels compare incoming sensory signals against those predictions and compute a prediction error. That error is sent upward, which updates the higher-level beliefs. The updated beliefs generate a new prediction, and the loop continues.
This architecture has an elegant property: it compresses information aggressively. Only prediction error needs to move upward. Anything already explained by the model does not need to be forwarded. The brain is not transmitting raw data. It is transmitting news. Only the unexpected part is worth sending.
So the brain is not a passive receiver. It is an active prediction engine. Much of what you see, hear, and feel is generated by the model itself. Sensory input mostly acts as a correction signal.
2. What It Explains#
A good theory explains many phenomena with one mechanism. On that metric, FEP is unusually powerful.
Perception: Your World Is a Controlled Hallucination#
If the brain is constantly generating predictions and sensory input mainly corrects them, a lot of familiar perceptual phenomena start to make sense:
The cocktail party effect. You can still follow a friend’s voice in a noisy room because the brain uses context to predict the next word and only needs a small error signal from the audio stream to correct itself. The model fills in a surprising amount.
Visual illusions. Your priors are too strong. The brain’s prediction overwhelms the sensory evidence, and the hallucinated structure gets treated as reality.
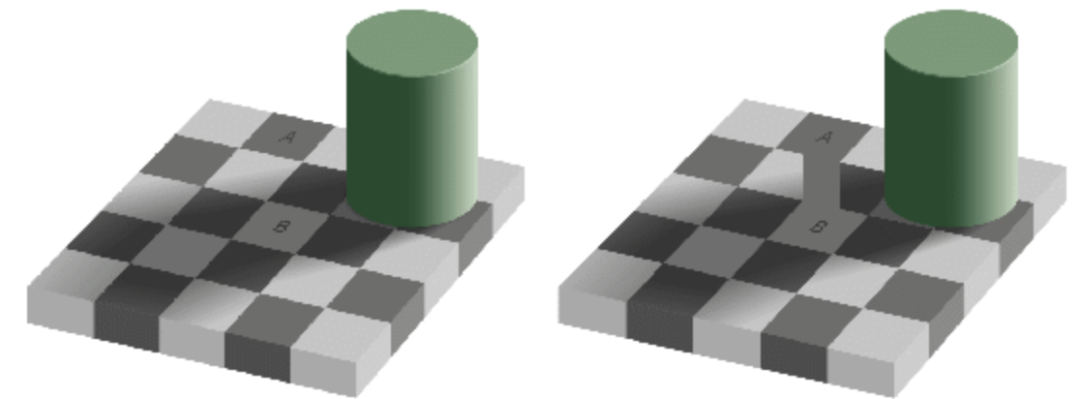
Change blindness. A major object in an image can change and you may not notice. If your model was not predicting that region, there is no prediction error there, and without a prediction error, nothing feels like it changed.
Emotion: What the Dashboard Is Reporting#
In the free-energy view, emotion is not some extra module bolted onto cognition. It is part of the system’s built-in dashboard. It reports the current state of uncertainty and error reduction.
- Anxiety
- The model expects a future full of uncertainty: “I don’t know what will happen, but I expect it to go badly.” This is a warning about high expected free energy.
- Curiosity
- The system detects uncertainty that looks reducible: “I don’t understand this yet, but I probably can.” This is epistemic value pulling you forward.
- Pleasure
- Prediction error is being successfully reduced. Either you guessed right, or events unfolded roughly as expected.
- Boredom
- Prediction error stays near zero for too long. Nothing new is being learned. The model is no longer improving.
- Surprise
- A positive prediction error. Reality turned out better, stranger, or simply different than expected.
This even gives a clean account of why music feels so good. Music builds expectations, violates them at the right moment, creates controlled surprise, and then resolves it. Music that is too predictable is boring. Music that is pure unpredictability is just noise. The best music lives in the narrow band between the two.
Curiosity and Exploration: Why You Don’t Hide in a Dark Room#
This is one of the sharpest implications of FEP.
If a system only minimized immediate surprise, the optimal policy would be obvious: hide in a dark, silent room and do nothing. No surprises. Problem solved.
But biological systems do not do that. They explore. They take risks. They play. They investigate. Why?
Because free-energy minimization is not only about the present. It is about expected future free energy.
Exploring an unfamiliar environment increases surprise in the short term, but it improves the model. And a better model means lower expected uncertainty across future states. In information theory, this is information gain.
Curiosity, exploration, scientific research, even the tireless play of children can all look like “creating unnecessary trouble” from the outside. Within FEP, they are perfectly rational: they accept short-term surprise in exchange for long-term certainty.
This also explains why learning something new often feels uncomfortable at first and satisfying later. At first, prediction error spikes. Then the model upgrades, and long-run free energy drops.
A core signature of intelligence is the willingness to absorb short-term surprise for long-term model accuracy.
Psychopathology: When the Prediction System Miscalibrates#
This framework also gives a useful computational lens on psychiatric conditions. Different disorders can be interpreted as different parameter failures in the prediction machinery.
- Autism spectrum conditions
- Priors may be underweighted and prediction errors overweighted. The issue is not lack of perception, but too much raw, unfiltered perception. Every detail arrives as news. The brain gets flooded by error signals and struggles to form stable high-level predictions. This offers one explanation for sensory overload, extreme sensitivity to change, and a strong preference for repetition and regularity.
- Schizophrenia (some symptoms)
- Priors may be overweighted and corrective error signals underweighted. The brain starts trusting its internal model too much, sensory correction fails to propagate properly, and hallucinations or delusions can emerge.
- Depression
- The generative model becomes locked into pessimistic beliefs: “things won’t get better.” If that prior becomes too strong, even positive evidence gets overridden. Negative predictions become self-confirming.
- Addiction
- Short-term free-energy reduction hijacks long-term minimization. A drug or habit offers an unusually reliable short-term route for reducing error or discomfort, so the system keeps choosing it even at severe long-run cost.
The point is not to rename common sense with new jargon. The value of the framework is that it is computational and modelable. In principle, you can specify which parameters have drifted out of range and design more targeted interventions.
3. What It Suggests#
A theory that only explains known facts is interesting. A theory that also tells you what to build is much more useful. That is where FEP becomes especially relevant.
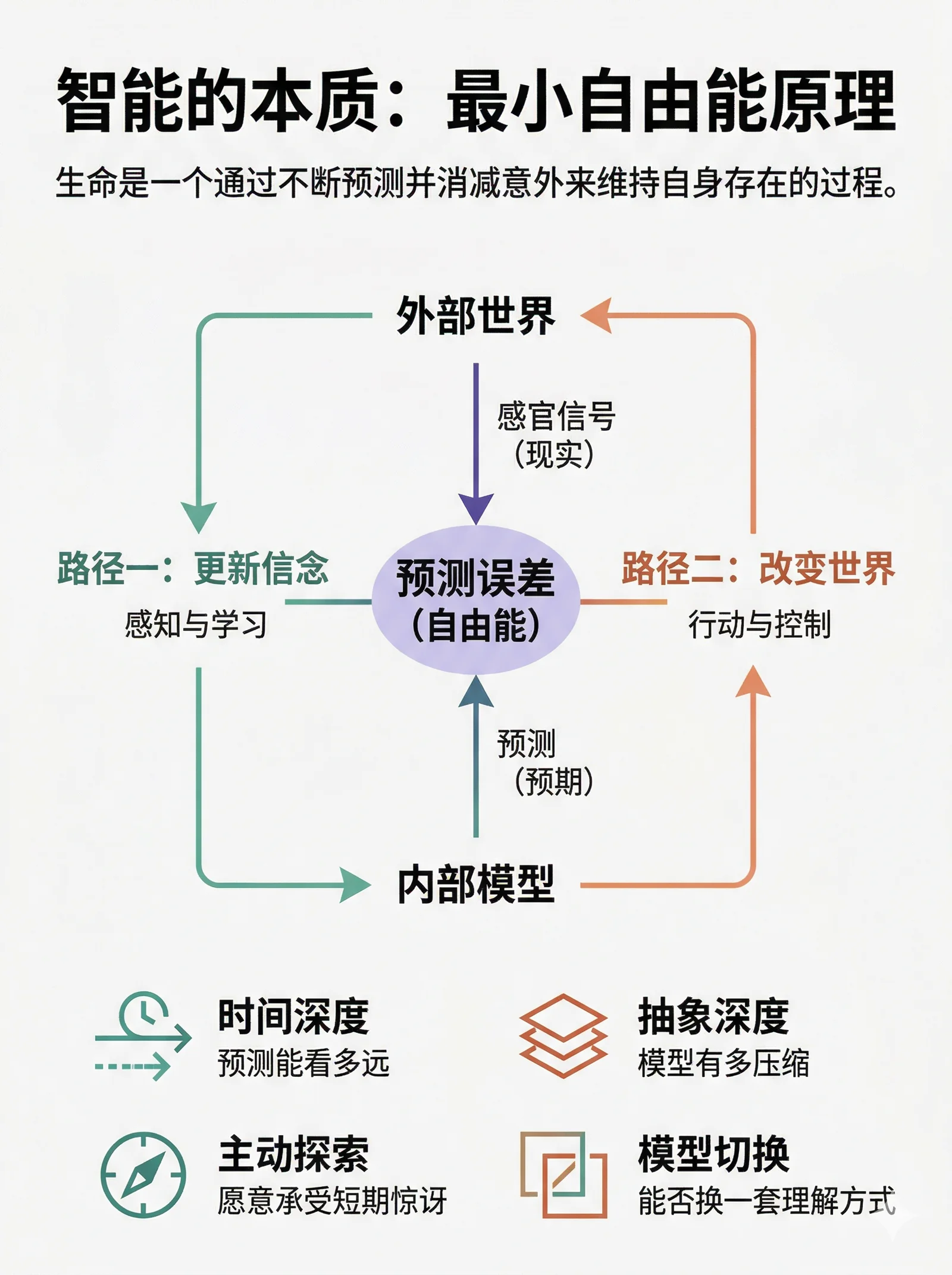
The Four Axes of Intelligence#
In this framework, intelligence is not a mysterious special substance. It is what emerges when a system becomes unusually good at minimizing free energy. The more intelligent the system, the better it does along at least four axes:
- Time horizon: how far ahead the system can predict
- A thermostat only reacts to the present. A squirrel can store food for winter. A human can save for retirement, or design policy around climate risks decades out. The longer the time horizon covered by the generative model, the more future uncertainty the system can reduce.
- Abstraction depth: how much compression the model achieves
- A frog’s visual system may effectively implement “small dark moving dot -> flick tongue.” Human cognition builds hierarchies from pixels to edges to objects to scenes to narratives to causal theories to mathematics.
Each layer compresses the error signals from the one below.
Newton’s laws reduced a huge amount of uncertainty about macroscopic motion with a tiny set of equations. That is model compression at an extreme.
Science itself is civilization-scale free-energy minimization: explain the most with the least. And because the free-energy objective naturally penalizes model complexity, it contains a mathematical version of Occam’s razor.
- Active exploration: how willing the system is to absorb short-term surprise
- A system that only optimizes the present hides. A more intelligent system goes out and samples the world to improve its model.
Curiosity is not a byproduct of intelligence. It is one of its core engines. A system with no curiosity has effectively opted out of long-run free-energy minimization.
- Model switching: whether the system can abandon the current frame
- The highest form of intelligence is not tuning parameters inside one fixed model. It is recognizing that the current model itself has failed, then inventing or switching to a better one.
Newtonian mechanics could not explain Mercury’s perihelion. Einstein did not patch the old frame forever; he built general relativity. In formal terms, this is search and jump in model space. In human terms, it is insight and paradigm shift.
What This Suggests About AI#
FEP is directly useful as a lens on AI systems.
- What are large language models doing?
- Predicting the next token. Training minimizes cross-entropy, and cross-entropy is expected surprise. So the training objective of an LLM is mathematically aligned with the first route to free-energy minimization: update the internal model. This also helps explain why LLMs can exhibit something that looks like understanding. To compress prediction error in language, they are forced to learn part of the world model behind language.
- What are LLMs missing?
- Two major things. First, they lack the second route: active inference. They do not robustly act on the world to make reality match their expectations. Second, they usually lack a persistent free-energy minimization loop. Each inference is mostly a stateless function call, not a system that must continuously preserve itself over time.
- What do agents add?
- The second pathway. Once a system has perception, action, and persistent state, it stops being just a passive predictor and becomes something closer to an active inference system. Under the free-energy lens, that is a real qualitative shift: from half a loop to a full loop.
- What would real general intelligence require?
- Strong performance on all four axes: long time horizons, deep abstraction, active exploration, and the ability to switch models when the current one no longer works. Current AI systems still hit obvious ceilings on all four. Being clear about where those ceilings are is already valuable.
What This Suggests About Personal Cognition#
This framework is not just academically interesting. It is also practically useful.
- What is learning, really?
- Updating your generative model. If something feels impossible to learn, the prediction error may simply be too large. If it feels dead and unstimulating, the prediction error may be too small. Efficient learning happens in the zone where surprise exists but remains tractable. Psychology calls this the zone of proximal development. In practice, it is close to what people mean by flow.
- How do you deal with anxiety?
- Two routes. Improve the model, or change the environment. Learn more to reduce uncertainty, or act to remove the source of it. What does not work is staying inside the same flawed model and running inference on it over and over again. That is just overthinking.
- Why leave the comfort zone?
- Because the comfort zone can become a dark room. Prediction error falls to zero, but the model stops updating while the world keeps changing. From a short-term perspective everything feels stable. From a long-term perspective hidden uncertainty is accumulating. Stepping out raises free energy now, but often lowers it later.
Appendix: The Formal Definition of Free Energy#
So far I have used intuition. If you want the strict mathematical version, here it is. If not, you can safely skip this section without losing the main argument.
The definition of variational free energy is:
$$ F = E_q[\ln q(s) - \ln p(s, o)] $$where:
- \(o\) is the sensory data you observe
- \(s\) is the hidden state of the world, the latent cause you do not observe directly
- \(q(s)\) is the brain’s belief about the hidden state, an approximate posterior distribution
- \(p(s, o)\) is the generative model, the joint probability of how you think the world works
This expression can be rewritten in two equivalent ways, each exposing a different meaning.
Form 1: an upper bound on surprise
$$ F = \underbrace{D_{KL}[q(s) \| p(s|o)]}_{\text{gap between belief and posterior}} + \underbrace{(-\ln p(o))}_{\text{surprise}} $$KL divergence is always non-negative, so \(F \ge -\ln p(o)\). Free energy is therefore an upper bound on surprise. You cannot usually compute surprise directly, because that requires integrating over all hidden states. But you can minimize free energy, and doing so pushes surprise down as well.
Form 2: accuracy vs. complexity
$$ F = \underbrace{E_q[-\ln p(o|s)]}_{\text{prediction error}} + \underbrace{D_{KL}[q(s) \| p(s)]}_{\text{model complexity}} $$The first term measures how well the model explains the data. The second measures how far the posterior belief moves away from the prior. So minimizing free energy means finding the best tradeoff between fit and simplicity. This is Occam’s razor in mathematical form.
Readers with a machine learning background will recognize this immediately: it is exactly the negative ELBO from variational inference. VAEs, variational Bayes, and EM all rest on the same mathematics. Friston’s move was to argue that this is not merely a computational trick. It may be a principle of life itself.
Closing#
Back to the opening line: “The point of life is to predict the future.”
Change the word order and it becomes much closer to the truth: life is not for predicting the future. Life stays alive by predicting the future.
Push that one step further:
Life is a process that preserves itself by continually predicting and reducing surprise.
Intelligence is that same process extended across longer time horizons, deeper abstraction, active exploration, and greater model flexibility.
This is not just a metaphor. It is a theory with mathematics under it, support from neuroscience, and a fairly direct engineering interpretation. With one principle, minimizing free energy, it links life, intelligence, perception, action, emotion, curiosity, learning, and creativity.
If this framework is even roughly right, then modern AI systems are not “inventing” intelligence from scratch. They are reimplementing, in a different substrate, something life has already been doing for billions of years.
Only the substrate changed: from carbon to silicon.