Back in 2019, I wrote about “Is running postgres in docker a good idea?” — Don’t run PostgreSQL in containers for production, because you’ll likely hit a pile of issues that simply don’t exist on bare metal or VMs.
Well, users of Docker’s “official” Postgres image just learned this the hard way during recent upgrades. Yesterday, PostgreSQL community veteran Gwen Shapira posted on X about this mess.

Picture this: you’re using Docker’s “official” postgres image, and this week’s latest PostgreSQL minor version drops — so you decide to upgrade. PG minor upgrades are supposed to be safe and simple, right? Just pull the latest image (I bet tons of people do exactly this), or if you’re slightly more careful, you might pull a specific version like 17.6 → 17.7. Well, you’re screwed either way!
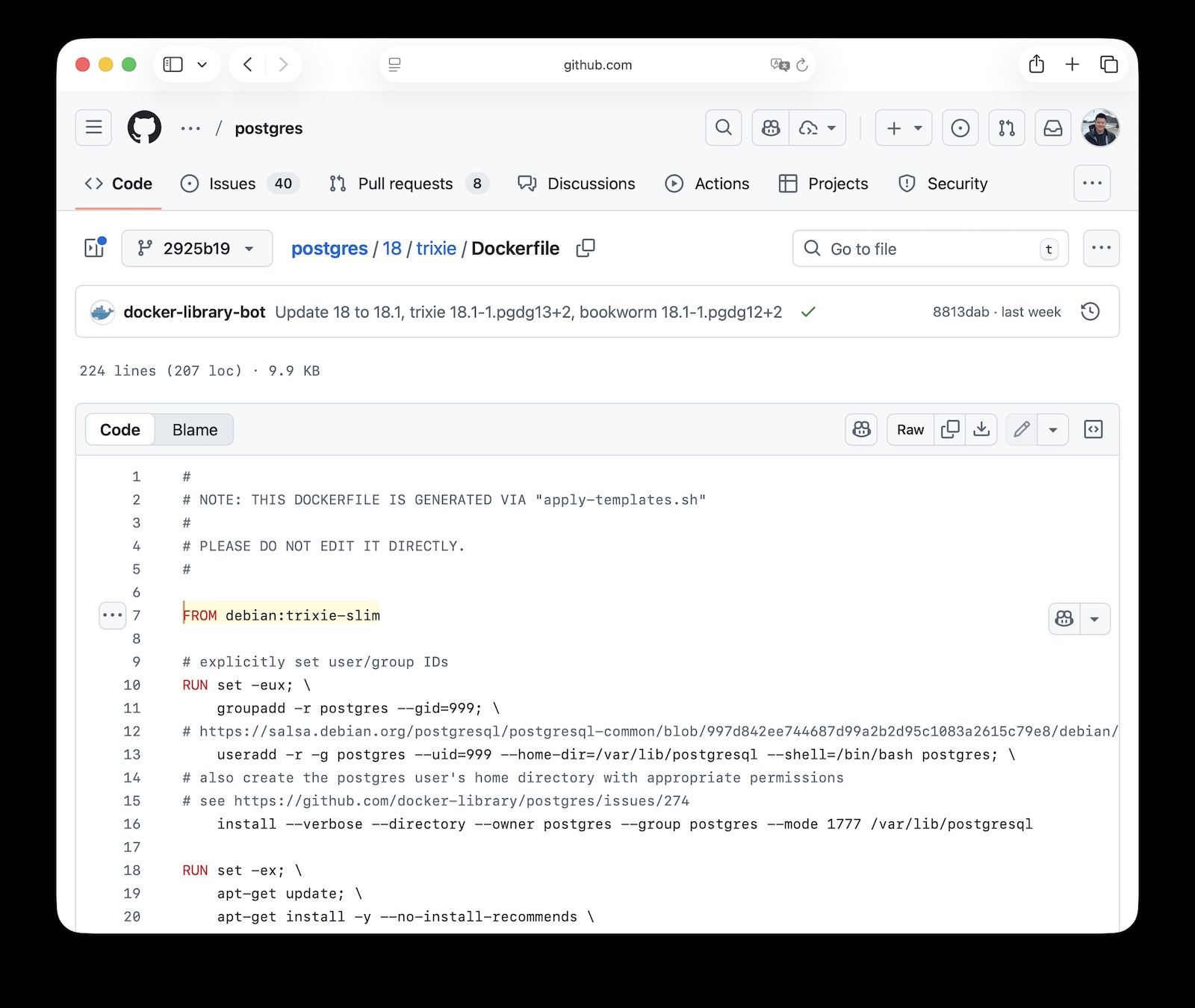
Unless your image tag explicitly includes the Debian version number (like 17.6-bookworm), recent minor version updates actually smuggled in a major OS upgrade.
You think you’re upgrading from 17.6 to 17.7, but you’re also upgrading the underlying OS from Debian 12 to 13! This unplanned in-place upgrade will render your database indexes instantly obsolete! (Or worse!)
What Actually Happened#
Docker’s official PostgreSQL images are primarily based on Debian (they also offer Alpine versions, but most people use Debian). The maintainers state these images only support two Debian releases at a time. When a new Debian stable version launches, they upgrade the base image to the new version and drop support for the oldest.
Debian 13 “trixie” just came out, so Docker “helpfully” upgraded their postgres image from Debian 12 “bookworm” to Debian 13 “trixie” underneath.
This caused a jump in the C library (glibc) version — Debian 13’s glibc went from 12’s 2.36 to 2.41, and between these versions, collation rules changed. That’s where things went south.
Database indexes fundamentally rely on sorting, which is defined by collation rules — and these rules aren’t set in stone. Whenever collation rules change, database clusters using the old rules need rebuilding — at minimum, indexes need rebuilding. Otherwise, you risk data corruption. What production database doesn’t use indexes? The result: “instant index obsolescence” and performance collapse, at least until you rebuild all indexes. Worst case? It could affect database constraints, data consistency, partitioned table behavior, and more.
The impact is massive. On DockerHub, the postgres image is one of the most downloaded — over a billion pulls total, about 17 million in the past week alone.
Many users just docker pull postgres and call it a day. Even if you specified a PG version like 17.6, without the Debian version, you’re still toast.
Emergency Mitigation#
For those running Docker’s “official” postgres containers in production, my advice: immediately switch to images with locked PG + Debian versions (like 17.6-bookworm), at least before your next minor upgrade or re-pull. When upgrading, always use version tags like 17.7-bookworm.
Also, don’t even think about upgrading directly from 17.7-bookworm to 17.7-trixie in place. Any change involving glibc (major Linux distro versions) requires logical migration — either through logical replication for blue-green deployment, or pg_dump logical export. Unless you’re a savvy PG veteran who cleverly specified PG built-in locale provider with C/C.UTF-8 when initializing your cluster.
Long term, you’re better off migrating to bare metal/VM database deployments. I’ve covered this in “Is running postgres in docker a good idea?” and “Is Putting Databases in Docker a Good Idea?” — The more complex your architectural juggling act, the harder you’ll fall when things go wrong!
If you absolutely must use containers, find a decent third-party Docker Postgres image. Even that’s better than this “official” amateur hour.
Why Collation Matters#
So why did this happen? I dove deep into this in “Localization and Collation in PostgreSQL”.
The simple takeaway: always use C.UTF-8 as your global collation. In PostgreSQL 17+, force the use of PG’s built-in locale provider instead of the OS glibc collation.
When you actually need specific locale rules (like Chinese pinyin sorting), just declare them explicitly in your DDL/SQL — use ICU collation, not the OS!
The issue is that (at least before PG 17) PostgreSQL heavily depends on the OS localization library for string comparison and sorting, a core function provided by glibc — and glibc’s collation rules change! Glibc versions update with every major Linux distro release. This means for production, you typically can’t just copy PG physical files from system A to system B and expect them to work — unless you’re using PG17’s built-in collation, which isn’t the default.
When running
initdb, use--locale-provider=builtinand--builtin-locale=C.UTF-8
At PGConf.Dev 2024, Jeremy Schneider’s Collations from A-Z keynote explained this in detail. The PostgreSQL dev team recognized this as a real problem, so last year’s PG 17 introduced built-in collation — no more relying on OS glibc collation, though it only supports C and C.UTF-8 rules. For a deeper dive, I highly recommend reading that material or watching the PGConf.Dev 2024 video.

23 Common Collation Myths — All Wrong!#
- Putting words in order is simple
- The way computers and people put words in order doesn’t change
- Changing sort order is rare
- Changing sort order is intentional
- Indexes are the only thing corrupted
- Users can rebuild the impacted objects
- My database doesn’t have any characters from that uncommon language with a sort order change
- My database understands all of the characters that are in it
- The Postgres warning message about “wrong collation library version” will be displayed to someone
- Postgres can always know what version of C Libraries are installed on the OS
- You can extract collation parts from old glibc, build separately, and install on new systems to fix issues.
- ICU solves everything
- ICU never had a huge sort order change like the glibc 2.28 fiasco
- Assume Devrim and Christoph are happy to build old ICU versions for you
- Sort order doesn’t change in library updates with just patch version changes
- Sort order doesn’t change in library updates with NO version changes
- Postgres doesn’t yet have builtin collation that avoids all corruption risks
- Postgres
CandC.UTF-8are the same- Sort order doesn’t change in
C.UTF-8- Collation provider is only for sort order
- CTYPE doesn’t change in
C.UTF-8- Users want DB-wide linguistic sort
- Postgres isn’t likely to get a new builtin collation solving these problems
Fortunately, PostgreSQL 17 introduced built-in collation, solving these problems. My PG distribution Pigsty accordingly adopted this feature in v3.4.0.
— All PG 17+ clusters uniformly use the built-in locale-provider with fixed C.UTF-8 collation. For pre-17 versions, we use the OS’s C.UTF-8 collation, falling back to C if the OS is too ancient to support C.UTF-8 (yes, they exist!).
The benefit: with built-in collation, no matter how the OS messes around, PostgreSQL sorting remains unaffected. Even if you upgrade the underlying OS, no index rebuilding or data corruption worries.
“Official” ≠ “Reliable”#
What PostgreSQL experts consider “common sense best practices” clearly isn’t that common. At least Docker’s “official postgres image” severely lacks these known best practices. As Gwen said: having “official” in the name doesn’t mean “responsible production behavior”.
The postgres image on DockerHub is widely used (supposedly the most downloaded), yet its quality is frankly concerning to PostgreSQL experts. This “official” refers to Docker’s “official,” not the PostgreSQL community. It’s riddled with anti-patterns and painful to use.
Ultimately, this so-called official image is an extremely crude wrapper: install via apt from PGDG APT repo, then run a hacky init script. This image works for POC, development, testing, and learning, but it’s light-years away from production readiness.
Production Databases Shouldn’t Use Containers#
Even if you dodged this minor version upgrade bullet with Docker Postgres containers, you’ll likely hit other landmines. Like the default 64 MB shared memory segment; writing directly to Overlay FS; extensions disappearing on replicas; running two PG instances on one volume and frying your data; bizarre replica setup procedures…
These container-specific problems that simply don’t exist on bare metal/VMs — I discussed many in “Is Putting Databases in Docker a Good Idea?”. But clearly, the community keeps discovering new “surprises” (scares). Running databases in containers still hasn’t reached the long-term equilibrium of running on bare Linux.
Engineering details like locale configuration are numerous and definitely not solved by a docker pull of some “official image.”
My Pigsty has nearly 100,000 lines of pure code just to properly run PostgreSQL,
clearly not something an “official image’s” few hundred lines of Shell/Dockerfile scripts can cover.
Actually, some third-party PostgreSQL-over-Kubernetes vendors provide much better PG containers than this “official” version. But honestly, they’re still hampered by containers themselves — a bunch of K8S/Docker masters optimizing like crazy still struggle to match PG running bare on Linux. For database veterans, it really feels like scratching an itch through a boot.
Docker is indeed convenient. I use it for stateless services, batch compilation tasks, sometimes as cheap VMs for testing, or quick database feature testing. But when it comes to production, I firmly say “no” to running databases in containers (— Redis might be the only exception).
How Should You Install PostgreSQL?#
So if not containers, how should you deploy PostgreSQL?
Databases like PostgreSQL are special software tightly coupled with the operating system. The ideal state is running bare on Linux — simple, direct, stable, reliable, no extra performance overhead or management burden.
Many think this is complicated — dealing with YUM/APT repos, official mirrors being slow or blocked, then being clueless about configuration and tuning after installation. That’s all ancient history. My open-source PG distribution Pigsty is designed specifically for running enterprise PostgreSQL services directly on Linux.
curl -fsSL https://repo.pigsty.io/get | bash;
cd ~/pigsty && ./configure
./install.ymlCurrently, I provide native PostgreSQL kernels (6 major versions from PG 13-18) on Debian 12/13, Ubuntu 22/24, EL 8/9/10, ARM/x86 — 14 mainstream Linux distributions, 8 different PG kernel flavors, nearly 100 ecosystem tools and 430 extensions. All packaged into one-click deployment with built-in monitoring, high availability, and PITR — a production-grade solution. Plus, I maintain a China mirror of the official PGDG repository.
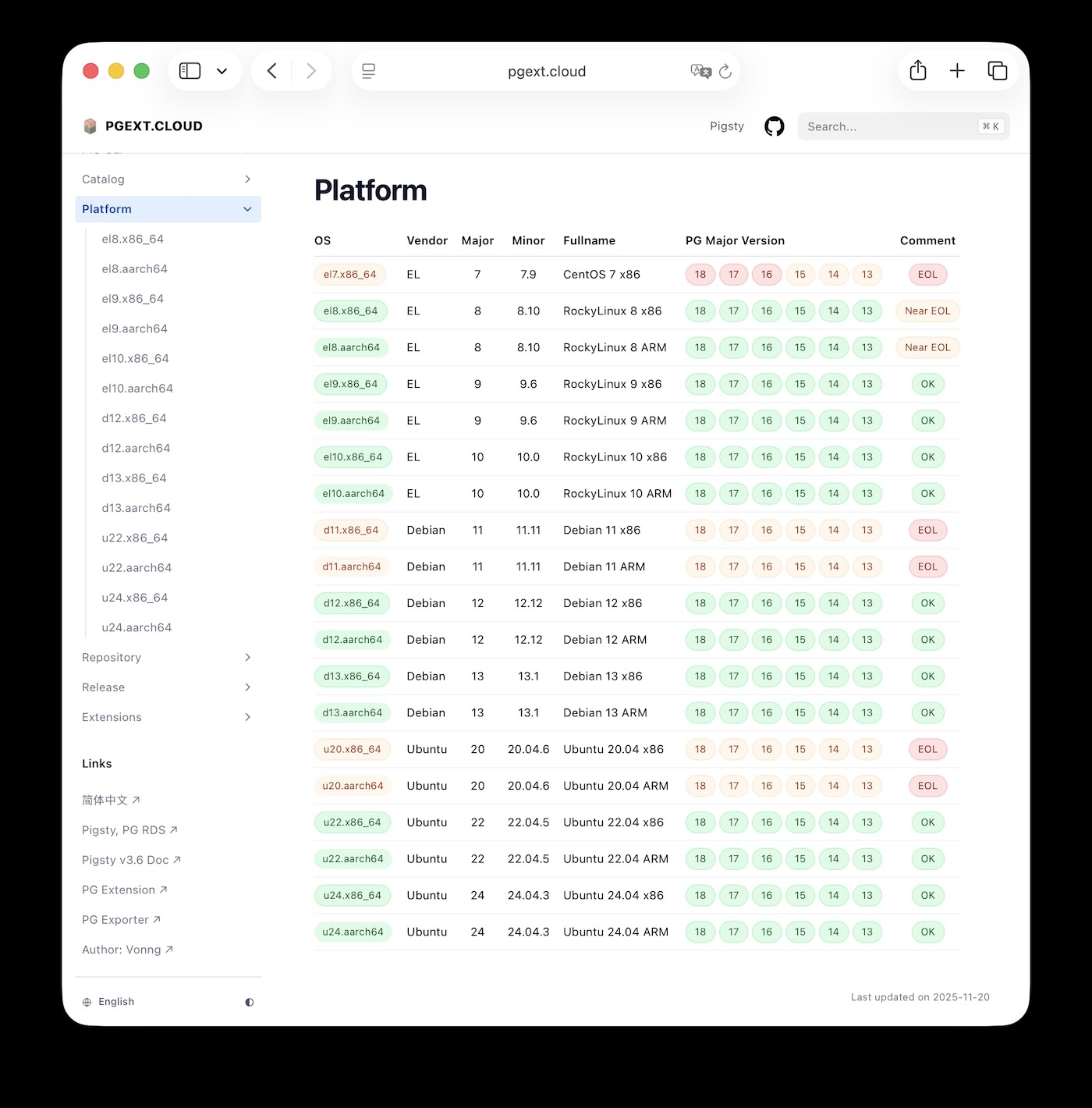
Honestly, it’s grunt work. We’re talking tens of thousands of RPM/DEB packages. Various test combinations, upstream changes — all need attention. I thought about it — just make a Docker image, lazy and easy, throw it to users, let them run it on whatever OS they want. But as a large-scale production solution I’d use myself, I decided to do the “right but hard” thing — provide the ability to run the entire PostgreSQL ecosystem directly on 14 mainstream Linux distributions.
After all, the “official image” also installs from repos using APT…
Best of all, Pigsty’s extension and mirror repos are independent. If you don’t want a full distribution, you can freely use our APT/YUM repositories to install native PGDG kernels and all those tools and extensions.
OK, commercial’s over. This post covered why you shouldn’t run PostgreSQL in containers for production. Next time, I’ll detail PostgreSQL installation practices — If not containers, how should I install PG!

Further Reading#
Is It a Good Idea to Put Databases in Kubernetes?
Is Putting Databases in Docker a Good Idea?
Kubernetes Founder Speaks Out! K8s Is Being Devoured!
Docker’s Curse: Once Thought the Ultimate Solution, Now “Guilty as Charged”?