

3 AM. Database alerts are blowing up.
You throw the alert info at a “top-tier” DBA Agent. It’s well-read — knows the PostgreSQL docs inside out, writes beautiful diagnostic SQL, can recite every kernel parameter from memory. It freezes: What’s the cluster topology? Where are the primary and replicas? How do I check the dashboards? Where are the logs? How was the last similar incident resolved? What tool do I use to do what?
It knows nothing.

Meanwhile, the agent next door — running a mediocre model but deeply wired into the full ops environment — has already identified the root cause, completed the failover, and filed the post-mortem.
The principle is simple: a mediocre local who knows the terrain beats a genius dropped into unfamiliar territory. That’s home court advantage. Intelligence without context is idle. An agent without a runtime is vapor.
OtterTune: A $12M Lesson#
In 2020, CMU’s database rockstar professor Andy Pavlo and his students founded OtterTune — AI-powered database auto-tuning. Top-tier academic team, $12M in funding, targeting PostgreSQL and MySQL. Impressive pedigree.
The product pitch boiled down to: give me a connection string, and AI will tune your database.
In June 2024, OtterTune shut down. The stated reason was a failed acquisition. But in my view, the real problem was: what you can do with a connection string just isn’t worth much.

Through a connection string, you can see slow queries in pg_stat_statements, config parameters in pg_settings, stats from a few system views. Then what? Twiddle a few knobs, optimize a few queries. That’s it.
But real database operations go far beyond this. A connection string connects to one PostgreSQL instance, but in the real world you’re dealing with clusters — primaries, replicas, offline standbys, sync backups. Above clusters, there’s horizontal sharding. At the top level, hundreds of clusters belonging to different business units. Beyond the database itself, you need backup status, HA component health, connection pool metrics, host CPU/memory/disk/network metrics. All of this lives outside the connection string.
An agent with only a connection string is like someone trying to understand a room by peeking through the keyhole — extremely limited visibility. Worse: the things you can do through a connection string are exactly what a raw LLM already handles well. Ask Claude or GPT to look at a slow query and it gives solid optimization advice. If an LLM can do what you do out of the box, where’s your moat?
OtterTune’s fundamental mistake was a runtime problem: it tried to do ops without an operational environment. Optimizing an abstract, bare PostgreSQL — it had a powerful brain but no hands, no eyes, no body. Like asking Stephen Hawking to do gymnastics.
PS: I know they’ve started a second venture, again doing PostgreSQL tuning. Hope they get it right this time.
Manus: The Real Core Is the Sandbox#
If OtterTune is the cautionary tale, Manus is the success story.
In March 2025, Manus appeared out of nowhere and became an instant phenomenon. Many people studied why it succeeded, focusing on its accumulated Markdown prompts or which LLM it uses.
Wrong target.
Manus’s real core isn’t the prompts or the model. It’s the VM sandbox — every user session runs in an isolated cloud Linux VM with a full filesystem, browser, shell, and code interpreter. The agent works inside this deterministic environment: reading/writing files, executing code, browsing the web, deploying apps.
Manus themselves said it clearly: “The power of Sandbox lies in its completeness.”
It’s this complete, deterministic sandbox that unleashes the model’s full capability. Without the sandbox, the same model is just a chatbot. With it, it becomes an agent that actually gets things done. And Manus has swapped underlying models multiple times — GPT to Claude — performance stayed solid throughout.
The recent viral hit OpenClaw proves the same point. It earned the “AI with hands” label not because the underlying model is superior, but because it deeply integrates with the host OS — filesystem, shell, browser, calendar, messaging apps all wired through CLI. Drop it into a blank cloud VM, stripped of those local hooks, and it’s just another chatbot.
Manus and OpenClaw validate the same thing: the LLM is the brain, but what really matters is the body.
Brain, Body, and Determinism#
Let’s push the Manus insight one level deeper.
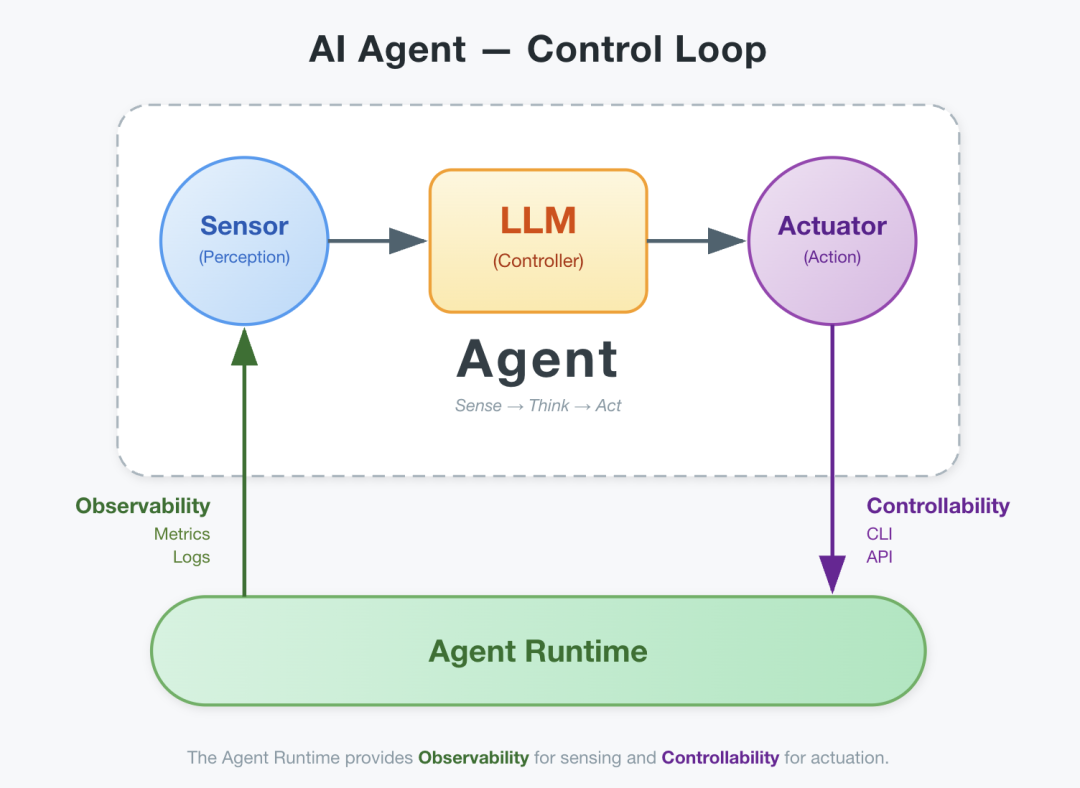
Biologically, intelligence requires three components: sensors (perceive the environment), decision-makers (process information), actuators (act on the environment). A creature with a brain but no body isn’t an intelligent agent — it’s a brain in a vat.
Agents are the same. The LLM is the decision-maker, but you also need sensors and actuators — i.e., observability and controllability. Together, these form the agent’s body. And for this body to function, there’s a prerequisite: determinism.
You can’t drop a brain into an unfamiliar environment and have it operate a weirdly-shaped robotic arm. The brain must “know” its body — which signals produce which actions, which feedback means which state. Brain and body need a stable, predictable protocol between them.

That’s the essence of a runtime: the agent’s deterministic body.
For a DBA Agent, a complete runtime means:
Sensors — full-stack observability. Not just what a connection string can see, but host metrics, connection pool stats, HA component heartbeats, backup progress, and internal database statistics — all organically fused, providing layered visibility from single instances to the entire data platform.
Actuators — full-stack controllability. Config changes, HA failover, backup/restore, rolling upgrades. Not calling someone else’s API, but directly shaping the infrastructure. If you’re just wrapping cloud vendor APIs, your agent is forever capped by the original author’s imagination.
Determinism — predictable behavior and auditable records. Same operation, same conditions, same result. Every step logged, every change reversible. Non-deterministic environments can’t produce deterministic outcomes.
Five years ago, when I started building PostgreSQL monitoring, I hit this exact problem: if you want the best monitoring system, you can’t rely on just a connection string. A connection string gets you something, but “something” is miles from “good.” To push observability to the limit, you must control the runtime — directly shape the infrastructure. That’s the pivotal moment that evolved Pigsty from a PostgreSQL monitoring project into a full-blown PostgreSQL distribution. What’s true for monitoring is true for management, and even more so for intelligence.
OtterTune had a brain but no body. The outcome was predetermined. Manus built a deterministic body (sandbox), and the brain’s power was finally unleashed.
A DBA Agent’s Body: Only Three Options#
Let’s use a concrete scenario — the DBA Agent. A coding agent’s context is a code directory. What’s a DBA agent’s context?
What is a DBA agent’s body? Who can provide it?
Option 1: Cloud vendors. RDS, Cloud SQL, Azure Database — monitoring, alerting, backup, HA, all included. But it’s someone else’s body. Your agent can only move within the vendor’s sandbox. Ops knowledge accumulates on the vendor platform, locked in. Switch clouds and it’s back to zero. If you’re building an agent on top of cloud APIs like OtterTune did, your design ceiling is the cloud API’s ceiling. This isn’t a body — it’s a cage.
Option 2: Kubernetes. K8s Operators can theoretically provide automated ops capability. But K8s introduces massive unnecessary complexity for databases — storage orchestration, network policies, stateful management, CRD abstraction layers upon layers. An agent doing database ops on K8s needs to grok an order of magnitude more concepts than just managing the database directly. K8s abstraction layers create enormous impedance, pushing the agent further from what it actually manages — the database itself. This isn’t providing a body — it’s strapping on a bulky spacesuit.
Option 3: Pigsty. An open-source PostgreSQL distribution that provides a full-stack deterministic runtime directly on bare Linux. Complete observability covering host-to-database monitoring, production-grade HA with automated backup/restore, 444 extensions out of the box, entire infrastructure managed as IaC.
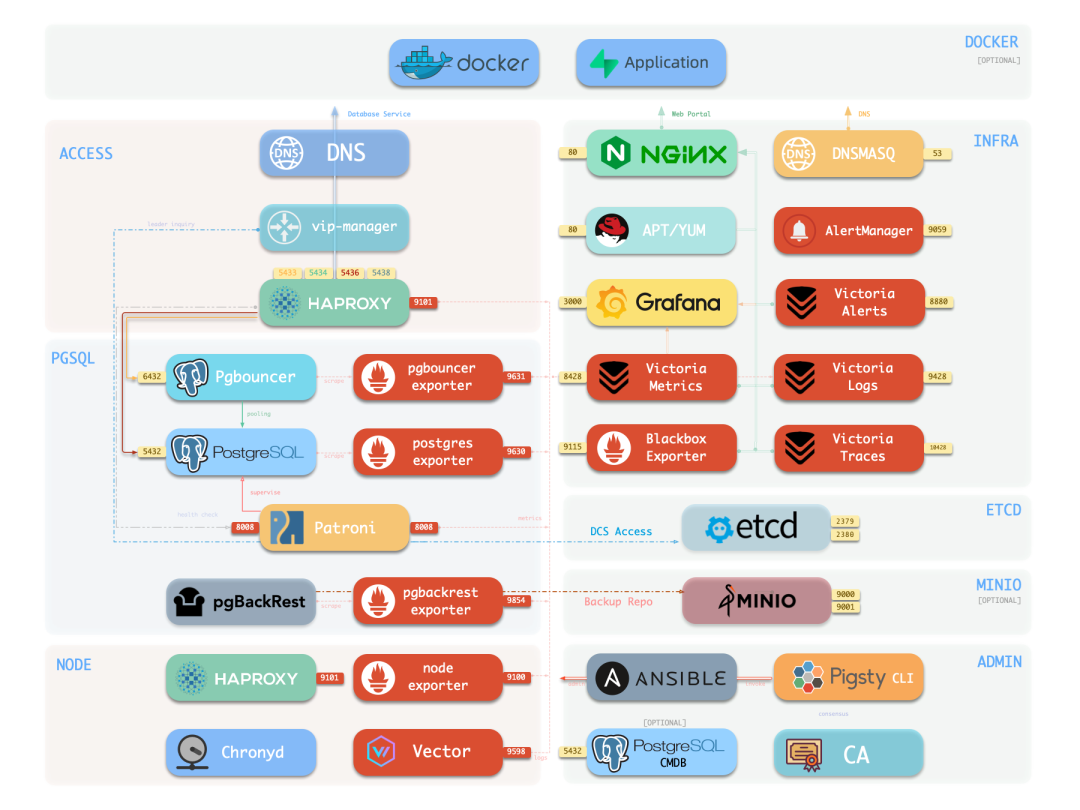
The difference between Pigsty and cloud database runtimes: it’s an open-source, free body that belongs to you. Every layer of the runtime is open — agents can directly read metrics, query logs, invoke standard ops interfaces. No black boxes. No walled gardens. Ops knowledge accumulates on your own infrastructure. Runs on any cloud, or from your laptop to your data center.
The difference between Pigsty and K8s: no unnecessary abstraction layers. The agent faces the database and OS directly. Short operation paths. High determinism. To use an analogy: cloud vendors are a rented theater — well-equipped but full of rules, expensive, and you can’t take the set pieces when you leave. K8s is an over-engineered theater where it takes three days just to learn how to turn on the lights. Pigsty is your own theater — well-equipped, clean layout, actors perform freely, and everything you build belongs to you.
Someone’s Already On Stage#
The Tsinghua University database team started working on this in 2024. Their D-Bot project explores autonomous fault diagnosis, root cause analysis, and repair recommendations in a complete Pigsty ops environment. The choice itself is telling: not poking at a remote connection string, but working inside a full runtime with monitoring, tooling, a knowledge base, and operational interfaces.
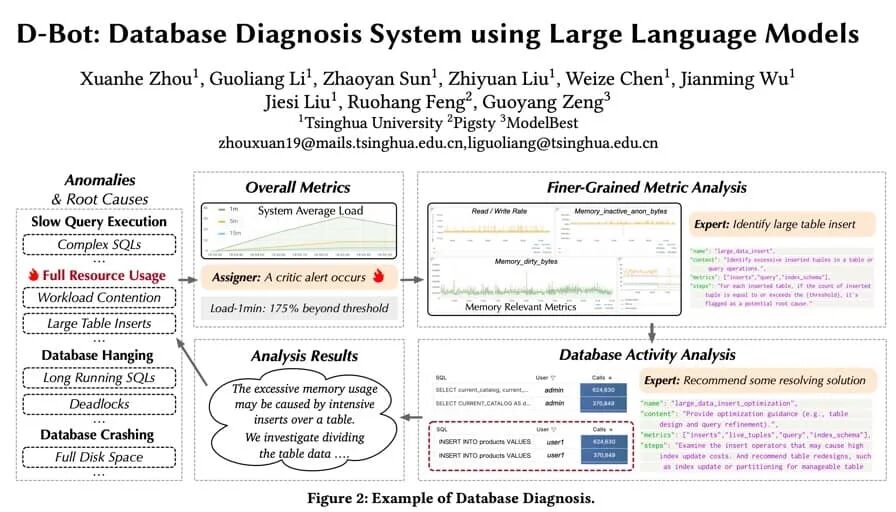

I contributed to this VLDB paper: D-Bot: Database Diagnosis System using Large Language Models
Academic research needs reproducible environments, and Infrastructure as Code naturally delivers this. Same config deployed a hundred times, identical environment every time. That’s exactly the determinism agents need. Meanwhile, I’m building a DBA Agent myself. Who understands a runtime better than the person who built it? On an open runtime, academic teams explore boundaries, infrastructure builders refine the core, community developers contribute ideas. An ecosystem is forming.
If you’re interested in DBA agents, Pigsty might be the best proving ground. It provides everything a PostgreSQL service needs in a real enterprise environment — full HA with PITR, and best-of-breed observability.
Dragons Come and Go, Territory Stays#
Back to 3 AM.
Same alert, but this time the agent runs on a complete runtime — inside its own body. It sees the anomaly curve on the monitoring dashboard, pinpoints the root cause from logs, confirms cluster topology and primary/replica status, completes the failover via standard procedure, verifies post-failover health, and generates a post-mortem report. Fully automated. Fully auditable.
The model might be GPT, Claude, or some open-source model — doesn’t matter. The agent itself might just be a few simple Skills and a CLAUDE.md file — also doesn’t matter. The moat in the agent era isn’t a smarter brain; it’s a more deterministic body. Inside this deterministic body, a simple CLAUDE.md file is enough to make a mid-tier LLM perform at a mid-level DBA’s competence.

OtterTune spent $12M proving: a brain without a body doesn’t work. Manus proved with a sandbox: give the brain a deterministic body, and it creates miracles. Dragons arrive one after another, each stronger than the last. But the local who’s been cultivating home turf for years keeps building deeper moats.
Dragons come and go. Territory stays. That’s the real moat of the agent era.





