

Yesterday the “cyber Bodhisattva” Cloudflare suffered its worst incident since 2019. For six hours, core network traffic couldn’t be delivered. ChatGPT, X, Spotify, Uber—everyone felt it.
Root cause: a permission change on ClickHouse made the bot-detection feature file twice as large (200 rows), exceeding a hard-coded limit inside a Rust bot-management daemon, which then flagged huge swaths of traffic as bots and blocked them.
Cloudflare published a detailed postmortem this morning. I translated it below with added notes.
Cloudflare outage – 18 Nov 2025#

At 11:20 UTC, Cloudflare’s network began failing to pass core traffic. Users saw error pages saying Cloudflare itself was broken.
No, it wasn’t an attack. A ClickHouse permission change caused a query to output extra rows into the bot-management “feature file.” The file doubled in size, got pushed to every server, and the routing software that consumes it has a lower size limit. Result: crash.
The team first suspected a mega DDoS. Once they realized the feature file was the culprit, they stopped distribution and rolled back to the previous version. By 14:30 most core traffic was back, though parts of the network remained overloaded for hours. Everything stabilized by 17:06.
Cloudflare apologized repeatedly: with their footprint, any outage is unacceptable. A six-hour core-traffic halt hurts everyone.
Incident overview#
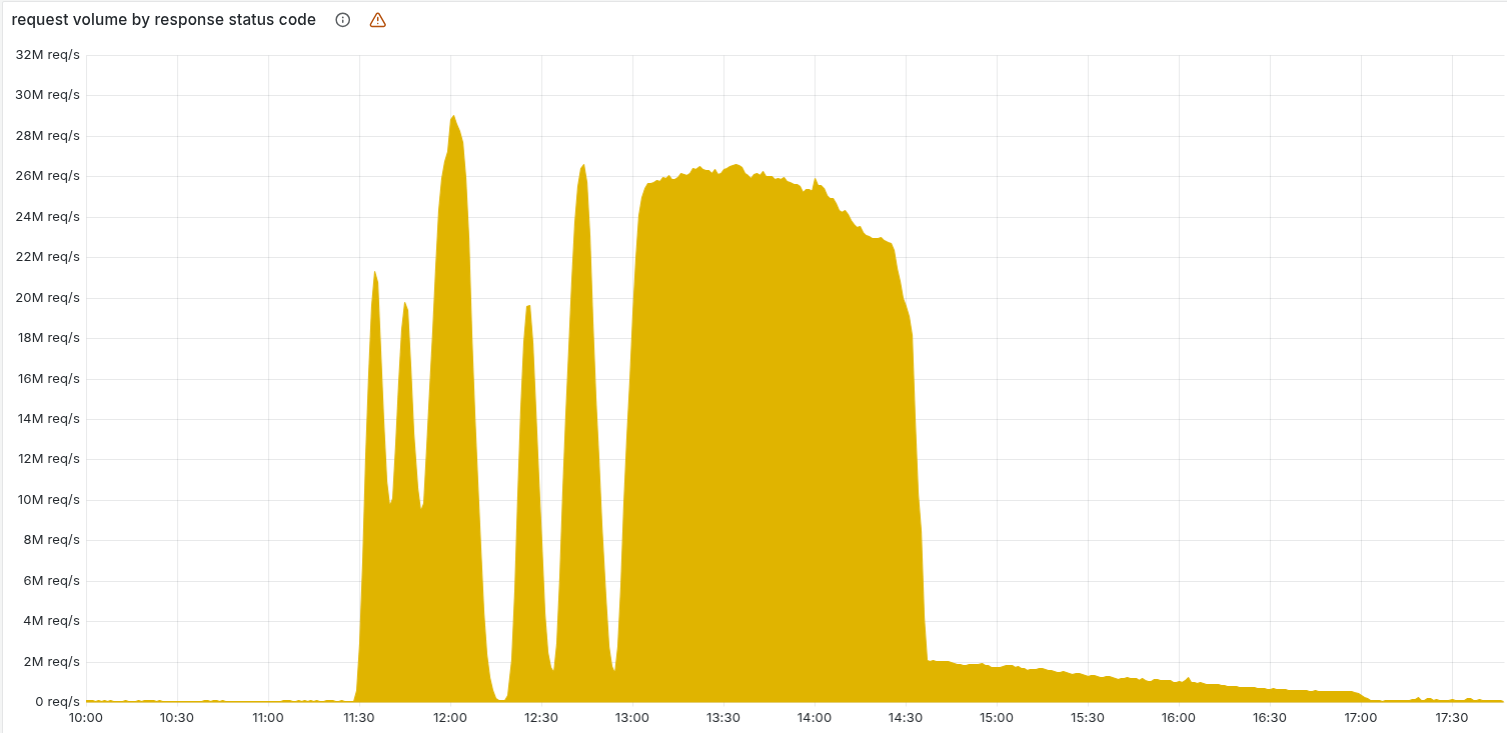
Below is the HTTP 5xx graph. Normally it hugs zero; after 11:20 it spiked and oscillated. The oscillation was because the feature file regenerates every five minutes on a ClickHouse cluster that was rolling out the permission change. When the query ran on an updated node, it produced the bloated file; otherwise it produced the normal file. So every five minutes the network flipped between healthy and broken.
That oscillation confused the response team and initially pointed them toward an attack hypothesis. Once every ClickHouse node had the new permissions, the output was consistently wrong and the oscillation stopped.
The issue persisted until 14:30, when engineers halted the generator, injected a known-good file into the distribution queue, and force-restarted core proxies. The tail on the graph represents hot restarts of unhealthy services; by 17:06 the 5xx rate was back to baseline.
Impacted services included:
- Core CDN & security – returning HTTP 5xx
- Workers – scripts unable to run
- Workers KV – control plane operations failed
- Access & ZTNA – auth policies misfired
- Pages, Turnstile, R2, Durable Objects – downstream failures
Timeline (UTC)#
- 11:05 – ClickHouse access-control change deployed
- 11:20 – First 5xx spike (feature file with duplicates deployed)
- 11:32–13:05 – Investigation focused on Workers KV slowdown and cascading failures; traffic-shaping attempts failed. Incident bridge opened at 11:35.
- 13:05 – Workers KV and Cloudflare Access patched to bypass the new core proxy version (fell back to older, less-broken proxy)
- 13:37 – Root cause confirmed: bot feature file
- 14:24 – Feature generation halted, rollback file staged
- 14:30 – Good file deployed; majority of traffic recovered
- 17:06 – All downstream services restarted; full recovery
What actually broke#
Misreading ClickHouse metadata#
ClickHouse is sharded. Cloudflare uses a Distributed table in a default database, which fans out to per-shard tables in r0. Queries run with a shared system account. As part of a security hardening push, Cloudflare wanted distributed queries to run under the caller’s own account so they could enforce limits properly. Before the change, querying system.tables or system.columns only showed default objects. At 11:05 they granted explicit privileges so callers could also see the r0 tables they implicitly use.
A bunch of code assumed those metadata queries would only return the default schema. Example:
SELECT name, type
FROM system.columns
WHERE table = 'http_requests_features'
ORDER BY name;No database filter. After the permission change, the result set included both the distributed table and every backing shard table. The bot-feature builder ran exactly this query to build each feature. The row count doubled, so the generated feature file suddenly contained 200 entries instead of ~60.

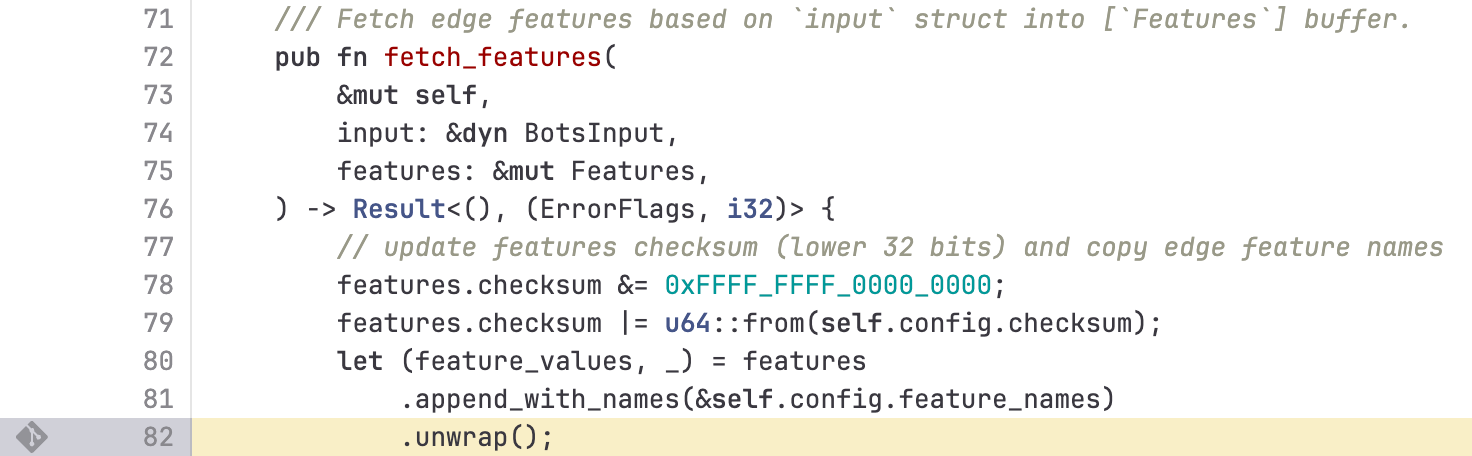
Memory preallocation + Rust panic#
The core proxy pre-allocates memory for bot features and caps the number at 200. That’s supposed to keep latency predictable; at the moment they only use ~60 features. When the inflated file hit, the loader exceeded the cap, tripped an unwrap() on an Err, and panicked:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err valueThat panic killed the worker threads, which in turn killed request processing, hence the wall of 5xxs.
Side effects#
Workers KV and Cloudflare Access depend on the core proxy. At 13:04 Cloudflare shipped a patch to let Workers KV bypass the proxy, which dropped error rates for all downstream systems, including Access.
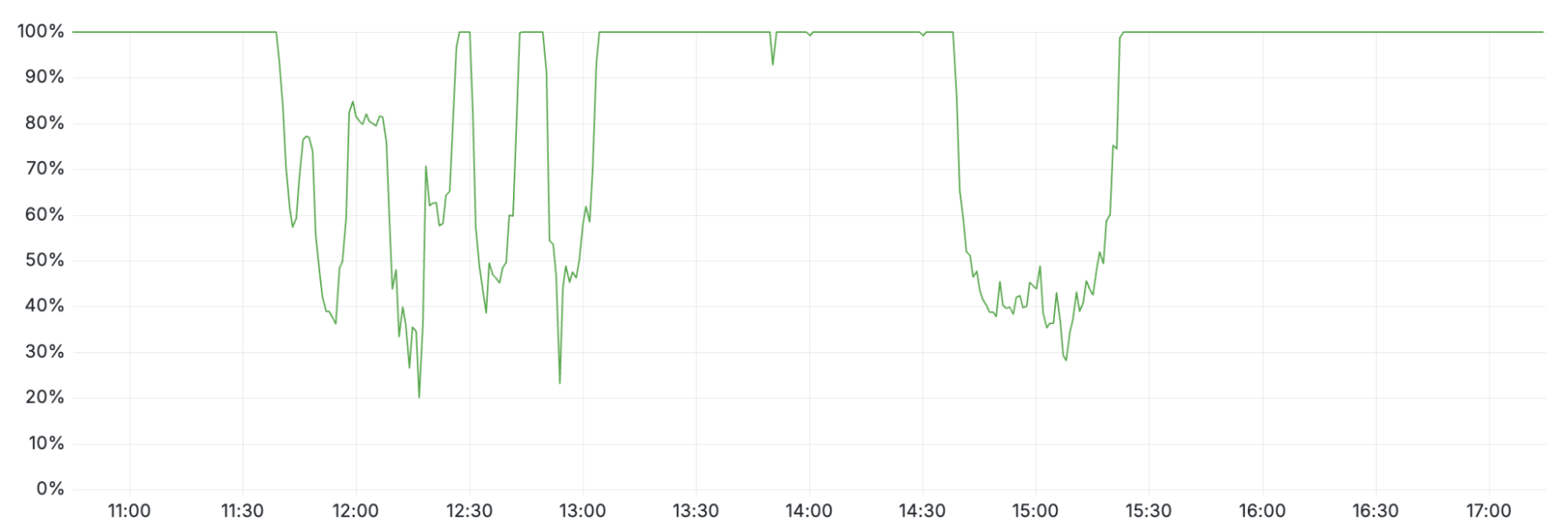
The dashboard depends on Workers KV and Turnstile, so it also degraded. Availability dipped from 11:30–13:10 and again from 14:40–15:30. The first dip came from Workers KV failures; the second came from a backlog of login attempts overwhelming the control plane once traffic returned. Scaling the control-plane concurrency cleared the queue around 15:30.
Mitigations and next steps#
Cloudflare lists the following follow-ups:
- Treat internally generated configs like untrusted inputs—validate & lint before rollout.
- Add more global kill switches for critical features.
- Prevent core dumps and error reporters from exhausting resources.
- Audit failure modes across the core proxy modules.
This was their most severe outage since 2019. They’ve had dashboard hiccups before, but nothing that halted the bulk of core traffic in six years. They know it’s unacceptable.
My commentary#
I host pigsty.io on Cloudflare. It went dark along with everyone else; thankfully I had backups on Vercel (pgsty.com) and a mainland mirror at pigsty.cc. Irony alert: I had just upgraded from the free plan to the $240/year paid tier last week.
Even as a loud “leave the cloud” advocate, I still relied on Cloudflare for CDN because building one yourself is pain. Yet the “cyber Buddha” has racked up more and more large-scale outages lately. People understand that failures happen, but seeing the entire industry tripping over the same low-level mistakes gets old.
Another domino derby#
This postmortem reads like another domino run: ClickHouse permissions → bot-management feature file → core traffic routing. A tiny permission tweak inflated the feature set, hit a hard memory cap, and Rust unwrap() panicked. No defensive programming, no graceful degradation. The butterfly flapped wings, half the internet crashed.
Industry-wide malaise#
This isn’t unique to Cloudflare. Every major cloud has faceplanted recently:
- AWS’s Oct 2025 DNS catastrophe – busted DNS automation.
- Azure portal meltdown in Oct 2025 – bad config push.
- Google Cloud + Cloudflare global outage in Jun 2025 – IAM failure.
- GCP deleted UniSuper’s private cloud in May 2024 – fat finger.
- Alicloud’s Nov 2023 global outage – IAM/OSS cyclic dependency.
Cloud economics hit diminishing returns: the benefits of scale are getting eaten by the risks of complexity.
Complexity is a tax#
As I noted in “From Cost Cutting to Laugh-Cutting”, complexity is cost. Modern clouds stack insane amounts of components: thousands of microservices, Kubernetes everywhere, interwoven dependencies. As long as everything is quiet, it’s fine. Once something misbehaves, the complexity makes diagnosis and recovery brutally slow. You can’t just throw more brains at it; the system’s cognitive load exceeds the team’s capacity. That’s when you get multi-hour, multi-continent outages.
Take AWS’s Oct 20 DNS faceplant as an example: a distributed DNS updater bug took down half the internet. At normal scale you’d just fix DNS with Ansible in five minutes. At AWS scale you need bespoke distributed components, and the fix looks comically clumsy.
Worse, the internet keeps concentrating onto a handful of providers. One misconfig now nukes half the web. The blast radius is systemic. We’re putting every egg in a single hyperscale basket.
Where do we go from here?#
Maybe it ends like power grids and airlines: regulation. My Swedish sparring partner wrote “Cloud vendors need adult supervision; Cloudflare blew up again”, making the same argument.
If compute is supposed to become utility infrastructure, then shape it like utilities. Today’s giants hoard IaaS while also owning the PaaS/SaaS stacks above. That vertical integration concentrates too much power and risk. Maybe the answer is to separate IaaS from PaaS/SaaS, let the base layer become regulated public infrastructure, and keep the upper layers competitive.
Think of IaaS as the power grid: compute/storage/bandwidth as public resources. Over time they’ll probably be “nationalized” or at least tightly supervised. PaaS/SaaS should remain market-driven, like appliances sitting on top of the grid. Users could mix and match instead of being locked into one vendor’s vertical stack.
In that world, the cloud becomes as trustworthy as high-speed rail or the electrical grid. Until then, even a personal site like pigsty.io has to brace for “cloud collapses.”






