

I recently did a recorded livestream on PostgreSQL and AI. The host asked a lot of good questions, and I gave some answers.
The recording goes out Tuesday night. I am publishing the fuller written version of my views here, including quite a bit I did not say on air, with some extra expansion and cleanup. Hopefully it is useful.
Where Is PG Now?#
Q: What is PostgreSQL’s position in the database world today?
PostgreSQL has become the de facto standard of the database world. It now occupies roughly the same place in databases that the Linux kernel does in operating systems. The whole ecosystem is concentrating around PostgreSQL, and that trend looks irreversible. To borrow Andy Pavlo’s half-joking line from a CMU database seminar, other databases are now in the position of “a 55-year-old man waking up pregnant.”
Given that reality, everyone is moving toward PG: vendors that used to belong to the MySQL camp, such as PlanetScale, Percona, and TiDB, are all trying to reposition; new databases such as RisingWave and GreptimeDB spoke the PG protocol from day one; all kinds of business software now default to PG. PostgreSQL is the king of databases right now. I do not think that position will face a serious challenge in the next 10 to 20 years.
Where things get interesting is at the PG distribution layer. Whether you use RDS, Aurora, Supabase, EDB, CloudNativePG, or Pigsty, the core is still PostgreSQL, but each comes with its own flavor and value proposition. That is where the meaningful competition in databases is happening now.
PostgreSQL Has Already Conquered the Database World
PostgreSQL vs MySQL: A War That Already Ended
A PostgreSQL Distribution Built in China, for the World
PostgreSQL Dominates the Database World. But Who Will Devour PG?
CMU PostgreSQL vs. The World Seminar Series
The PG Community’s Turn Toward AI#
Q: Over the past year, what has been the clearest sign that the PostgreSQL community is turning toward AI?
The clearest signal is capital. In 2025 alone, the PostgreSQL ecosystem saw more than $1.25 billion in acquisitions: Databricks bought Neon for $1 billion, and Snowflake bought Crunchy Data for $250 million. Those two deals sent a very clear message: in the AI era, databases are valuable infrastructure. PG ecosystem companies captured almost all the major funding in databases.
Neon also published one especially interesting data point: 80% of its database instances are created by AI agents. Of course, Neon skews toward indie developers and early AI adopters, so you cannot mechanically extrapolate that number to the whole market. But the direction is clear: the marginal entry point into databases is shifting from human developers to AI agents.
The technical signals are dense too. Extensions like pgai and pg_vectorize, which embed AI capabilities directly into PostgreSQL, are showing up quickly; Timescale is pushing “Agentic PostgreSQL”; all kinds of MCP servers now let agents talk directly to PostgreSQL. The community narrative is upgrading from the LLM-era line of “PostgreSQL can also do vector search” to the agent-era line of “PostgreSQL is the runtime for agents.”
That said, a lot of the AI enthusiasm is happening at the vendor and distribution layer, not inside the database kernel itself. At the core developer level, the PostgreSQL community has stayed steady and restrained. It has not been chasing trends or stuffing flashy AI or agent features into the engine. For example, in last year’s PG conference developer vote, there was very little interest in merging the pgvector extension into core. That restraint is itself a signal. It shows the PG community has a clear understanding of what belongs in core and what should stay in the ecosystem.
The Moat Around Agents: Runtime
PGFS: Using the Database as a File System
Stop Arguing, the Database Question in the AI Era Is Already Settled
What Did PG Get Right?#
Q: Why was PostgreSQL suddenly rediscovered in the AI era? What did it get right?
PostgreSQL did not suddenly get anything right. It has been doing the right thing all along: extensibility.
I made this argument in 2023 in PostgreSQL Is Eating the Database World. It later became close to a consensus inside the PG community, and community steward Bruce Momjian has echoed it many times in talks. The extensible architecture PostgreSQL has held onto for 30 years is what truly makes it “advanced.”
Take pgvector as an example. Roughly 8,000 lines of extension code, sitting on top of PostgreSQL’s 1.7 million lines of core code, already covers most real-world vector retrieval needs. The reason is simple: if you want to build a complete standalone vector database from scratch, you first have to solve HA, backup and recovery, ACID transactions, and all the generic database plumbing. That part alone is worth millions of lines of code. A team building a vector extension gets to stand on the shoulders of giants, reuse the whole PG ecosystem, and focus on a few thousand lines of domain logic.
The same pattern is now showing up in full-text search, analytics, and more. More and more pgvector-like extensions are emerging and taking down one database niche after another. That flourishing extension ecosystem exists because PG’s extensibility is so extreme. By contrast, MySQL still does not have a mature vector search capability even in the community edition. It largely missed this entire AI wave.
Whoever Integrates DuckDB Best Wins OLAP
pgvector and the Vector Database Track#
Q: What is
pgvectorstill missing for production? In what cases would you still prefer a dedicated vector database?
pgvector existed before ChatGPT took off. When it first appeared in 2021, it was a personal project. But once the AI wave hit in 2023, Neon, Supabase, and AWS all got involved. With that level of capital and engineering effort behind it, it has long since reached a professional standard.
At last year’s PolarDB conference, someone pulled a live benchmark stunt with pgvector and Milvus. Running on Intel AMX, pgvector was twice as fast as Milvus. Pretty funny.
What is even more interesting is that pgvector has now developed its own sub-extension ecosystem, extensions for the extension. Timescale’s pgvectorscale adds DiskANN. TensorChord’s VectorChord supports streaming index updates and advanced quantization on an IVF + RaBitQ architecture. pgvector still has room to improve under large-scale concurrent HNSW updates, and that is exactly the area these sub-extensions are trying to push forward.
At the two ends of the spectrum, there are still niches. If you only need a small lightweight vector store, you can look at options like Qdrant. If you are doing trillion-scale image search, like Taobao-style photo lookup, Milvus is still worth evaluating. But across the huge middle, for new AI projects and new AI applications, the default stack is now PG + pgvector. That point is basically not in dispute.
Are Dedicated Vector Databases Dead?
What Capabilities Does AI Need From a Database?#
Q: Agents are very hot right now, and we are also seeing all kinds of “Agent Native databases” and agent memory frameworks. What do you make of that?
Frankly, most databases on the market branding themselves as “AI Native” or “Agent Native” are still at the concept-marketing stage. Ask them what “Agent Native” actually means, and it is hard to get a technically defensible answer. Apparently adding vector support now qualifies as “AI Native.” It is the same movie we already saw with “cloud-native databases.”
In my view, this question has two layers: core needs and extension needs. Because you cannot enumerate everything an AI agent will need. Today it needs vector search. Tomorrow it may need graph queries. The day after that, maybe weight patches or emotion vectors. So the right strategy is not to explicitly pile up features, but to provide a kind of meta-capability: when new needs appear, the community can load them naturally through extensions.
PG is the clearest expression of that model. It can provide vector capability through pgvector, graph queries through AGE, BM25 full-text retrieval through pg_search or pg_textsearch, full JSON operations, plus GIS, time-series, and many other data models. A lot of those capabilities arrive as add-on extensions.
At the database kernel level, you do not need fancy AI-native tricks. You just need to do one thing extremely well: under the usual non-functional requirements like security and reliability, provide maximum extensibility. Functional requirements will grow naturally out of the ecosystem.
This path of evolution brings another huge side benefit: it collapses the cognitive nightmare of polyglot persistence. Problems that used to require gluing together a dozen different databases can now be solved inside one full-stack converged database with one SQL language. That dramatically reduces the cognitive burden for both agents and humans.
Of course, DuckDB is another database with strong extensibility, and SQLite counts for half. In my view, only databases with this property really deserve to be called databases for the AI era. The future belongs to data platforms that support agile parallel exploration, flexible composition, free extension loading, and synergistic effects.
Why PG Will Dominate Databases in the AI Era
What Capabilities Does an Agent Need From a Database?#
Q: Some people say “the database is the hippocampus of the agent.” What do you think?
The hippocampus is the part of the brain responsible for converting short-term memory into long-term memory and retrieving it. If you absolutely want a brain analogy, then maybe the vector query engine inside a database barely counts as the hippocampus. But the database itself is much larger than that. It includes storage engines, transaction engines, geospatial engines, document engines, and other components, each serving a different function. Memory also comes in many forms: working memory, long-term memory, episodic memory, semantic memory. The hippocampus is only one part of the picture.
Rather than saying the database is AI’s hippocampus, it is more accurate to say the database is the agent’s exosomatic memory system. Humans invented writing and books to compensate for the limits of the brain. Agents also need a persistent system of record to compensate for the limits of the context window.
In the broad sense, “exosomatic memory” can include file systems, object storage, and every other persistence layer. But the reason databases are better than file systems as the core memory infrastructure for agents comes down to two things.
First, structured relational query capability. When an agent retrieves memory, it does not just need to “find a similar passage” through vector search. It needs to join that memory with user profiles, historical behavior, and timelines. That kind of relational reasoning is simply not something a file system can do. It is the home turf of relational databases.
Second, structured governance. Multi-tenant isolation, fine-grained access control, which memories administrators can change, which memories team members and untrusted outside users are allowed to influence. Databases can solve all of this elegantly through RBAC and row-level security. File systems have permission control too, but databases give you table-level, row-level, and column-level governance. In multi-agent collaboration, that is a qualitative difference.
Agent memory frameworks are indeed flourishing right now, but from a moat perspective, those upper-layer frameworks mostly solve the “memory organization strategy” problem: what to store, what to forget, how to retrieve. The lower layer, storage, retrieval, transactions, permissions, still bottoms out in the database. The durable moat is the database underneath.
What Kind of Database Do Agents Need?
What AI-Relevant Features Are in PG 18?#
Q: What key features in PostgreSQL 18 matter for AI?
Database Cloning#
PG 18 has two features that matter a lot for AI. The most important one, in my view, is database cloning. This feature can instantly clone a large database using copy-on-write, without consuming extra storage. You can clone multiple copies and let agents modify the clones. Those modifications stay incremental. Once the result is verified, you can apply the approved changes back to the production database.
This gives agents a kind of counterfactual reasoning ability. Humans do this too: before acting, we simulate possible consequences in our heads. Agents cannot and should not directly modify important production databases. Database cloning gives them the safety precondition of verify first, act second.
More than that, it gives agents the ability to explore in parallel: fork multiple branches, try multiple paths in parallel, then pick the best one or merge results, much like Git in the code world. Coding agents already use Git to manage repository state and worktree to branch out for parallel exploration. Database cloning finally gives the data layer the same branching primitive.
Git for Data: Instantly Cloning a PG Database
OAuth Authentication#
Another interesting but underrated feature is that PG 18 supports OAuth login. In a future world of multi-agent networks and agent platform economies, agents will be able to log directly into databases with OAuth. That opens a lot of room for imagination.
There is already an early proof of concept. Look at Moltbook, basically a little lobster-themed social plaza. At heart it is just a Supabase instance, PostgreSQL wrapped with a REST API, and agents connect directly to the database to read, write, and interact. The end state might look like this: a database sits there, and the database itself is the application platform. Agents arrive at that database, each mapped to a user. With PG 18 supporting OAuth, agents log in directly, get their own permissions and private state tables, and also post into shared public-square tables.
I say “might” because this is still just a minimal prototype. Between a social experiment like Moltbook and a real “database as application architecture,” there is still a missing layer of convention: how does an agent discover the core tables inside a database? How are semantics self-described? How do you enforce fine-grained resource quotas? There are no standard answers yet. But PG already provides the base layer: identity, concurrency control, access control, transaction isolation. Those are all necessary conditions for multi-agent collaboration.
Database as Application Architecture
Database Choice Is Moving to Agents#
Q: In the agent era, how will database competition change? How will people choose?
This is a seriously underrated trend: the power to choose the database is moving from humans to AI agents.
Some users know nothing about databases. They just run Claude Code, and the agent searches the docs, evaluates the options, and completes the whole selection and deployment process on its own. That raises an interesting question: how does an AI agent “choose” a database?
My intuition is: searchable documentation. When agents make decisions, they read a huge amount of docs, best practices, and community Q&A. If one database has the most complete docs, the most active community, and the broadest best-practice coverage, agents will be more likely to recommend it.
That means documentation quality and community density may become more important competitive dimensions than raw performance.
This is not just theory. I have seen a very interesting signal in my own data: Cloudflare traffic to the Pigsty docs site has been rising at an astonishing rate. Human active users on the site are still under 100,000 by Google Analytics, but monthly PV is already around 50 million. A large share of that traffic comes from AI agents. Quite a few new users simply told Claude Code to “set up some PG,” and Claude Code brought Pigsty up by itself. The CLAUDE.md in the Pigsty directory contains a full documentation index, so whenever the agent needs something, it just goes and looks it up.
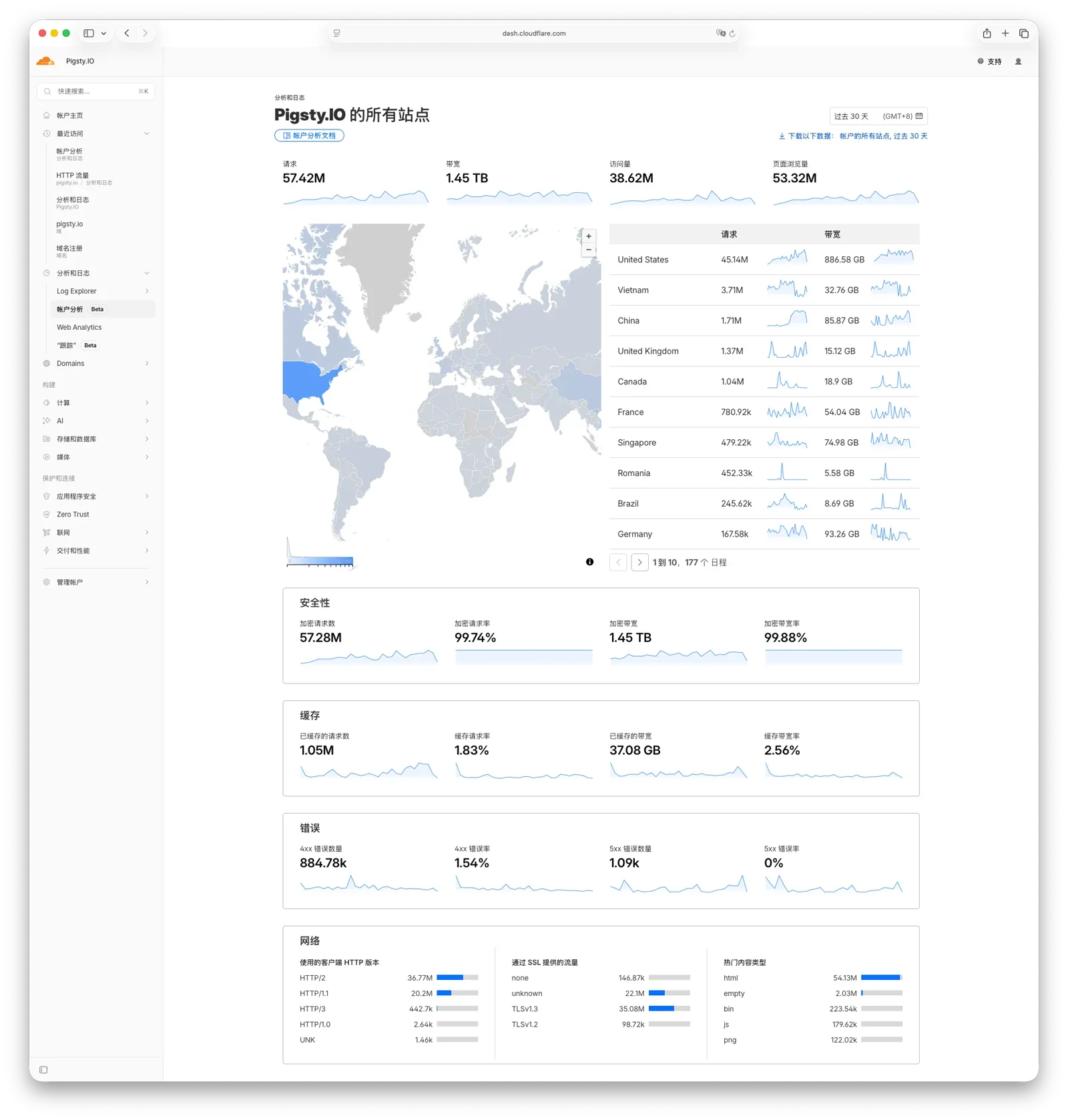
This creates a snowball effect in the AI era: better docs -> agents are more likely to recommend you -> more people use you through agents -> more practical feedback -> more best-practice docs -> agents understand you better and recommend you more accurately. Positive feedback loop, winner takes most.
PG has a huge first-mover advantage on this dimension. It has the most complete documentation and the most active community of any database. This may turn out to be the most important and most counterintuitive dimension of future database competition.
Will AI Replace the DBA?#
Q: If agents can choose databases, can they also replace DBAs?
The DBA population actually contains two very different roles.
The first is the DA, data architect, or data manager. That role is hard to replace. Its core value is not just judgment, but accountability. Put bluntly, this is the person who can take the blame when things go wrong. Just like AI can help do bookkeeping, but in the end a human accountant still has to sign. In situations involving data security, compliance, and architecture decisions, human judgment and responsibility are irreplaceable.
The second is the operational DBA. This role faces far more substitution pressure. In the end, the only unique value left might be the ability to take responsibility. In terms of pure capability coverage, AI may already be at 70% to 80%.
There is one subtle structural point worth noting: AI hits the middle of the value curve hardest. Top experts are less affected, because they are the ones steering AI and supplying the irreplaceable training signal and decision judgment. Newcomers are blank slates, and can often use expert-distilled tools to reach a mid-level standard quickly. The group getting squeezed hardest is the middle layer, the people who live on accumulated operational experience but have not yet formed truly irreplaceable judgment.
But DBAs have one structural advantage that often gets overlooked: AI’s impact on the middle of the value curve is much more violent in frontend and backend work than in databases. The reason is simple: AI agents themselves need databases. In the traditional IT stack, the database remains the core. DBAs already understand databases deeply. It is much easier for them to use AI agents to do frontend and backend work than for frontend and backend engineers to use AI to muddle through database work.
DBAs are also under pressure, but in this wave their opportunity to transform may actually be better than that of many other technical roles. They can use that structural advantage to arm themselves into something closer to “full stack” much faster. Of course, this is not a free pass. The barrier for frontend and backend engineers to do database work is also dropping quickly. The DBA’s structural advantage is a time window, not a permanent moat. Whether someone can complete that transition inside the window depends on the person.
Where Do Databases and DBAs Go in the AI Era?
Will the Cloud Eliminate DBAs?
AI Ripped the Software Facade Off
“Software Meltdown: When the Translation Layer Gets Flattened”
In the AI Era, Software Starts From the Database
AI Was Used as the Excuse to Lay Off 4,000 People, but Demand for Programmers Still Rose 11%
What Should New Engineers Do?#
Q: If junior and mid-level DBAs are replaced by AI agents, what advice do you have for newcomers?
AI agents create a brutal problem: they are cutting off the traditional path from apprentice to expert.
The old path was to learn under a mentor for three, five, or eight years, build intuition in real work, and eventually become the expert. That path is breaking, because the middle layer is disappearing and newcomers no longer have the environment where real experience used to form. The explicit knowledge that can be written down will be swallowed by AI. The thing that makes experts hard to replace, tacit and embodied knowledge, can only be formed in concrete environments. And those environments are increasingly closed to newcomers.
My advice to newcomers is to build real skills: software engineering ability + infrastructure knowledge. Root downward, reach upward.
Software engineering ability does not mean “being able to write code.” It means: how do you turn a fuzzy requirement into an executable plan? How do you design a maintainable system? How do you build complex projects with AI’s help? This is a whole new engineering practice. It is not the same thing as “chatting with AI.” Learn how to drive coding agents like Claude Code. Learn methodology frameworks like BMAD. Learn how to use AI for engineering, not just conversation.
Infrastructure knowledge means the things closer to the metal: operating systems, databases, networks, storage. These fields change slowly, have deep moats, and are less exposed to AI. They are sparse in training data, but lethal in production. AI applications and agents still have to run on infrastructure in the end. Find a domain where you can touch the lower layers directly and understand the whole ecosystem, for example, going deep on PostgreSQL itself instead of spinning in abstractions at the middleware layer.
When you connect both ends, understanding infrastructure downward and harnessing AI productivity upward, you become the new kind of full stack.
New Programmers in the AI Era: Where Do You Go?
The AI Era Survival Guide: Where Is the Biggest Upside?
Closing#
My personal view: PostgreSQL is already the biggest winner in the data world of the AI era.
Databases as an industry have survived for half a century. From hierarchical models to the relational model, from mainframes to distributed systems, from on-prem to the cloud, every paradigm shift has produced people declaring that “the old world is dead.” But what actually dies is never the database itself. What dies are the products that try to answer every problem with one fixed form.
That is the biggest irony in technology: when everyone is chasing the next shiny thing, what actually holds up the new era is often the plainest infrastructure. But PostgreSQL is not just plain infrastructure. It is infrastructure with the adaptive capacity to support evolution above it. A highly stable and disciplined core, plus a wildly thriving extension ecosystem. The magic that reconciles the two is called extensibility.





